Microsoft Inspire で HoloLends 使った翻訳デモがあったりして盛り上がりを感じたので久々に触ってみようと思いました。
今回は、話した音声を Speech to Text でテキスト化して表示するコンソールアプリを作ります。

開発環境はこんな構成です。
- Visual Studio 2019
- C#
- .NET Core
- Nuget package: Microsoft.CognitiveServices.Speech (v1.6.0)
プロジェクト作成と Nuget のインストール
Visual Studio で C# の コンソールアプリ (.NET Core) のプロジェクトを作成しましょう。
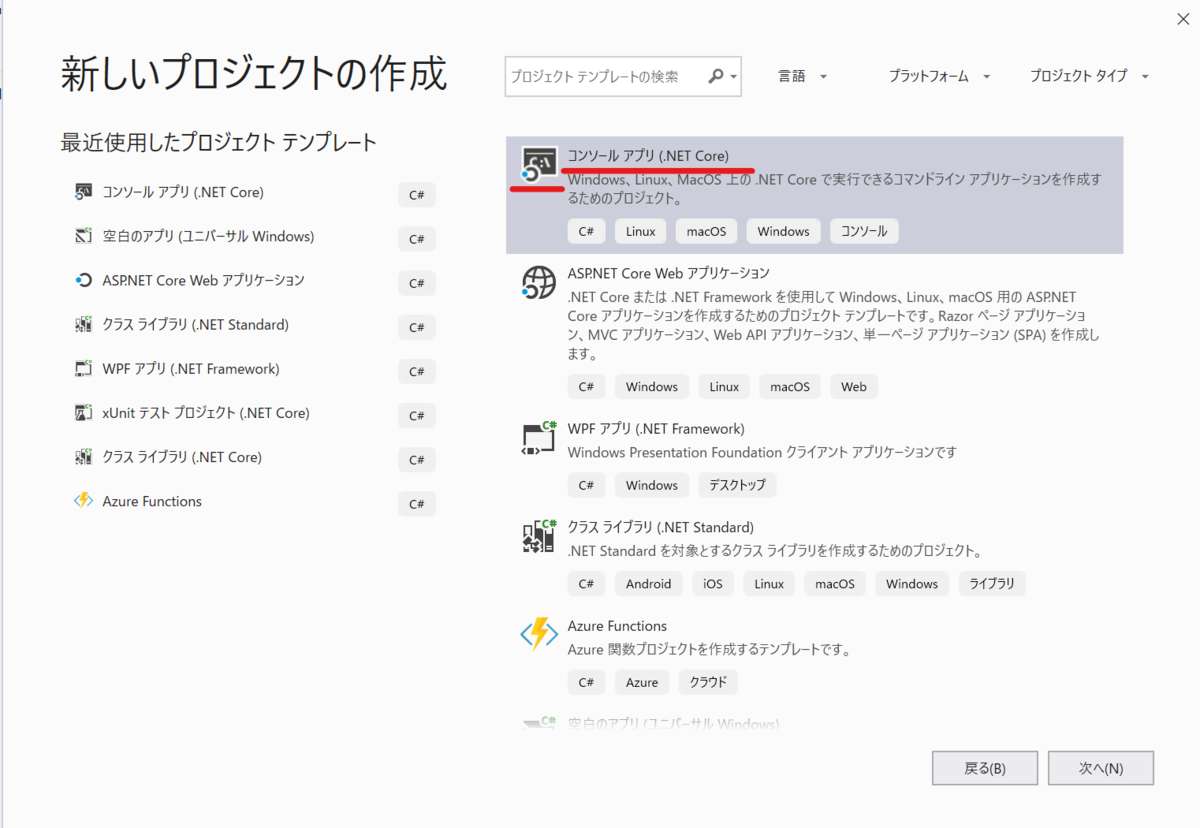
プロジェクト名とかを任意につけます(今回はプロジェクト名を「SpeechServiceConsole」としました)。
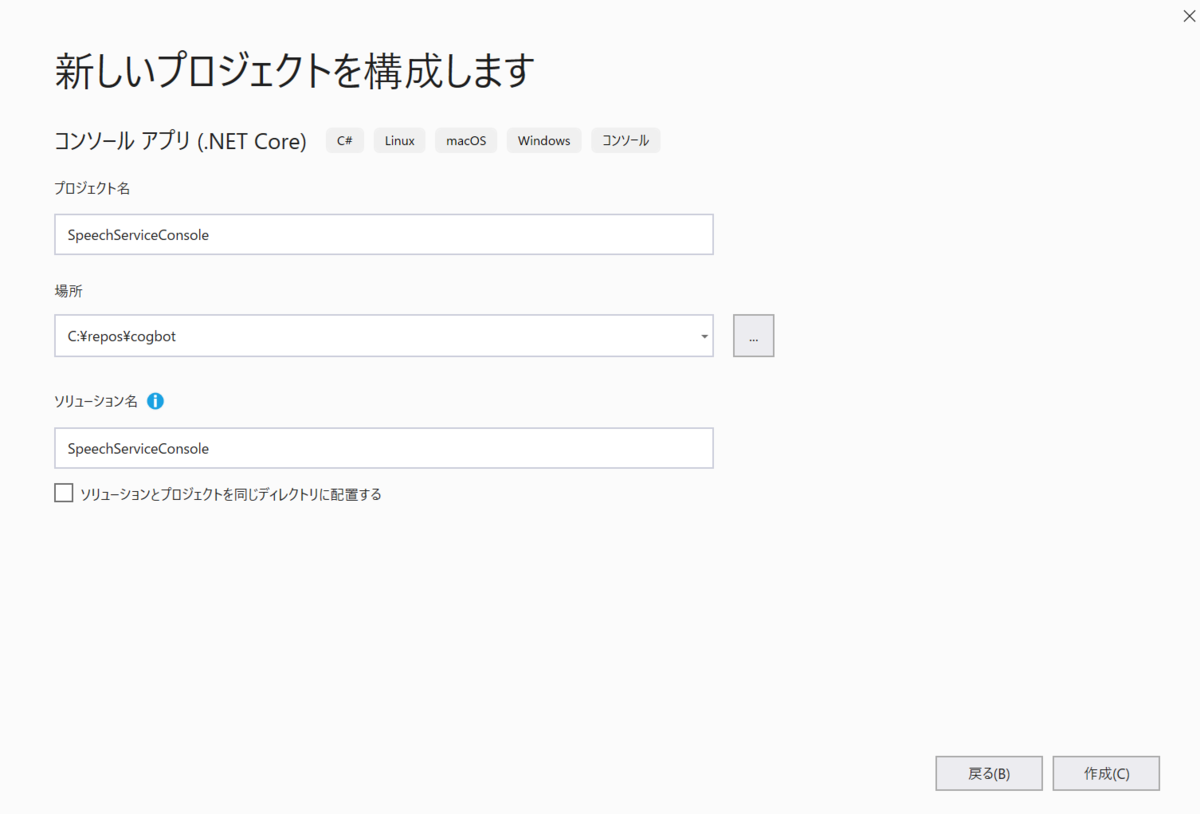
プロジェクトができたら、ショートカットキーCtrl + Q キー > クイック検索で「nuget」と入力 > 「ソリューションの Nuget パッケージの管理...」を選択します。クイック検索はよく使うものがサジェスチョンされるので、積極的に使えばより便利に使えて良い感じです。
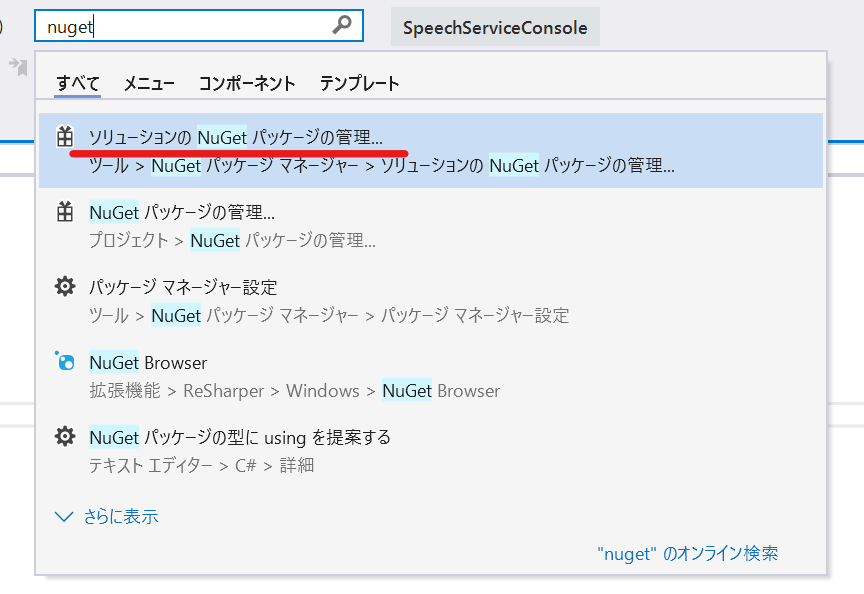
Nuget Pakage は、 Microsoft.CognitiveServices.Speech を検索してインストールしましょう。バージョンは現時点で最新の 1.6.0 です。
アプリの全体構造を実装する
Speech To Text で非同期処理をするので、とりあえず Main メソッドを非同期にしましょう。
static void Main(string[] args) となっている部分が非同期になってこうなります。
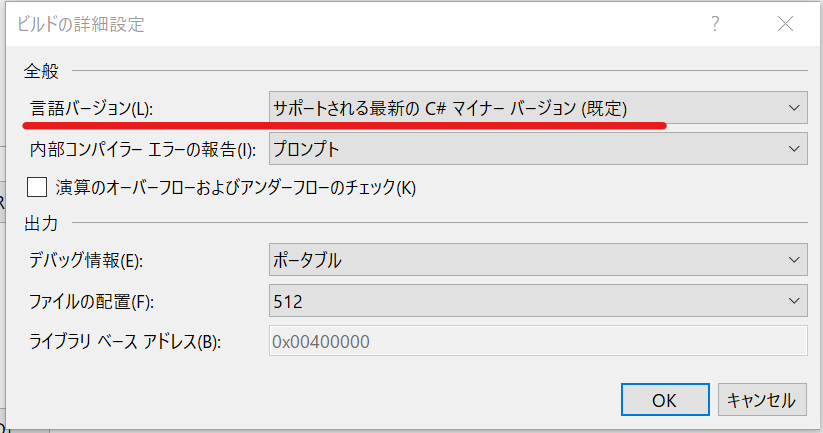
余談になりますが、もしここでエラーが出る用だったら、C# のバージョンがイケてないので修正しましょう。ソリューションエクスプローラーでプロジェクト名を右クリック > 左ペインの ビルド > 詳細 をクリックして...

言語バージョンを「サポートされている最新のC# マイナーバージョン」にしましょう。正確にはC#7.1以上で利用できます。
今回作るコンソールアプリはこんな感じです。
- メニューを選択する
Speech To Text をするか、音声翻訳する(今回のブログでは実装しないけど...)かを選べぶ - 選んだメニューを実行する (今回だと Speech to Text のみ)
- 話す言語を選択
- 処理を実行
メニューの選択について、具体的には以下のようにします。
- 1 を入力したら Speech To Text の実行
- 2 を入力したら 今回は実装しない Speech Translation の実行
- 0 を入力したら終了
- それ以外の入力だと再入力を促す
まずはこの構造だけ作ってしまいしょう。
27行目とかで ConsoleKey.D1 ってありますが、これは キーボードの 1 のことです。ConsoleKey.D2 は 2 です。数字だと後は察せれるかと思いますが、このキーの一覧は以下の公式ドキュメントにあります。
8-9行目は後ほど Speech Service のキーとリージョンの情報を入力するので定義しておきました。
また、11-13行目は遊び心で文字の色を変えたいので定義しました。
は、メインのメニューでやりたいことを表示しましょう。
先ほど書いた中身のないメソッド ShowMenu() を以下のように実装します。
ここまでで、デバッグ実行をしてみましょう。コンソールが表示されたら、1, 2, 0 以外を入力して再入力されたり、0を入力したらアプリが終了すると正常です。1,2を入力すると例外が発生しますが、これも現時点では正常です。
Speech To Text の実装
メインの Speech To Text の実装です。
ここでの動作は、さっきもちょっと触れましたが以下になります。
- 話す言語を選択
- 処理(今回だと Speech to Text を実行)
話す言語の選択を実装
まず、話す言語を選択させるメソッドを 新たに 追加して作成します。SelectLanguage メソッドとその中で呼んでる ShowLanguageMenu メソッドの2つです。これを独立して新たに作るのは、(今回は実装しない)音声翻訳のメソッドでも再利用したいからです。
キーの 1 を押したら日本語の言語コード、2を押したら英語の言語コードを返すように実装しています。
ここでは選択できる言語は日本語と英語だけにしてますが、他に話したい言語があれば公式ドキュメントの言語コードリストを参考に追加しましょう。
・言語サポート - 音声サービス - Azure AI services | Microsoft Learn
Speech To Text
ようやく Speech To Text の処理です。今回はダラダラと話す会話をテキスト化する実装を行います。
それ以外のコア機能として、15秒以内の発話のテキスト化や、カスタムモデルを利用したテキスト化などいくつかあります。興味がありましたら公式ドキュメントで確認しましょう。
・音声テキスト変換の概要 - 音声サービス - Azure AI services | Microsoft Learn
準備として2つのことをします。1つめは、以下の using ステートメントをプログラムの上部に追加します。
using Microsoft.CognitiveServices.Speech;
2つめは、以下の変数定義を const の変数が定義されている下(AppMessageColorの下あたり)に追加しましょう。
private static readonly TaskCompletionSource<int> StopRecognition = new TaskCompletionSource<int>();
では、最初にメソッドと中身で例外が発生するよう実装した RunContinuousSpeechRecognitionAsync() の実装です。
中の throw new NotImplementedException(); を消して、以下のように実装します。
SetEventHandler メソッドはまだ実装してないのでエラーがでますが、問題ありません。
Speech Service と通信していますが、そこは SDK の中でよしなにやってくれているので意識しなくてよいです。
最終的にキャンセルや停止の命令が飛ぶまで Speech To Text をし続けます。具体的な内容は後述のSetEventHandler メソッドの実装で明らかになります。
以下の2つのメソッドを新たに追加して実装します。
SetEventHandler メソッドがややごちゃごちゃしてますが、イベントハンドラーに処理を割り当てているだけです。特徴的なものとして Recognizing は、音声の認識途中の内容を出力します。Recognized で完成された一文章を表示します。
(だらだらと話したときの動作を見ると具体的に理解できます。)
今回は「ストップ」と発話すると Speech To Text が停止するようにしています。
では、最後に Speech Service のサブスクリプションキーの準備です。
サブスクリプションキーの取得
まず余談ですが、
サブスクリプションの取得時にリージョンを選択する必要があります。とりあえず試すなら安易に日本やアジアではなく、米国西部がお薦めです。理由は新しい機能が追加されるのが早いからです。Speech Service だと、以前からある標準音声の進化版、Neural Voice が徐々に展開中で、まだ使えないリージョンが多いです。対応可否は以下の公式ドキュメントから確認できます。
本題となりますが、
Azure のサブスクリプションをお持ちの人はそのサブスクリプションから取得しましょう。
もってない人は無料の試用版があるようです(私は使ったことないのでよーしらんです)。
以下の公式ドキュメントから手順を確認できます。
キーを作成したら、Azure の Portal から情報を取得しましょう。
作成したリソースの 概要 で情報が確認できます。
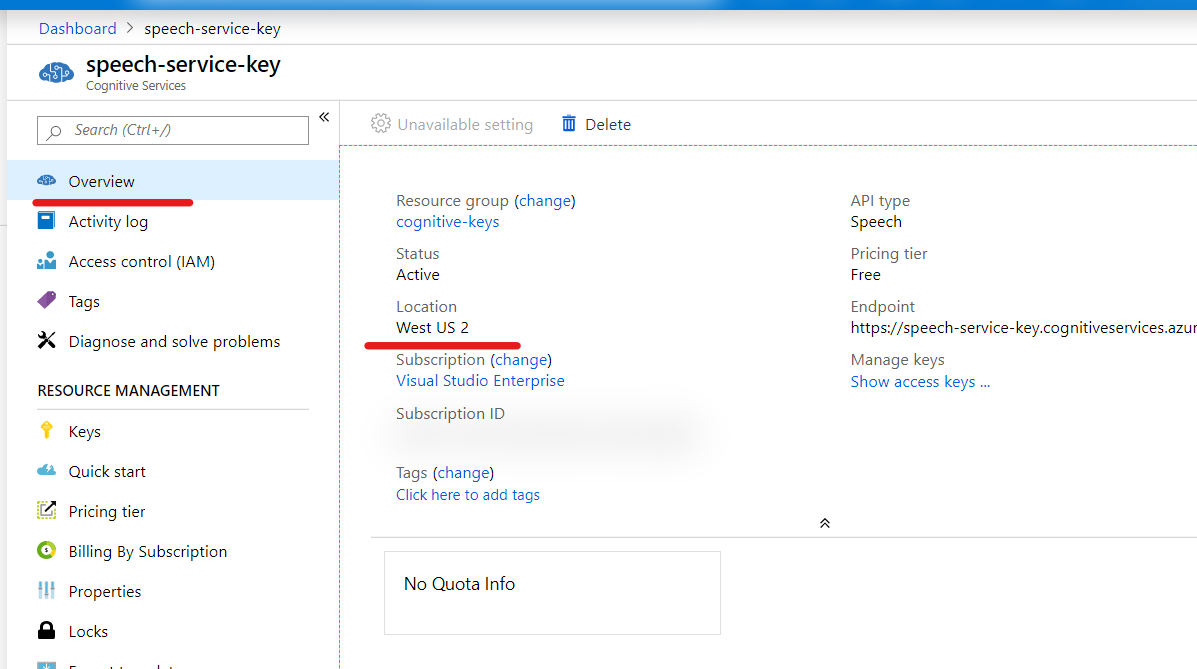
リージョンは、場所 (英語で Location って書いてあるとこ)からどのリージョンかを確認して、以下のドキュメントに記載のある Speech SDK パラメーター の値を確認して、プログラムの変数 Region に代入します。米国西部2なら westus2 となります。
リージョン - 音声認識サービス - Azure AI services | Microsoft Learn
キーは キーを表示 をクリックして値を確認し、変数 SubscriptionKey に代入しましょう。
動作確認
デバッグ実行して正常に動作しましょう。
コードの全体像は以下リンクにあります。
speech service demo: STT · GitHub
そのうち音声翻訳もやりつつ、Inspire でやってたデモの音声周りのところとか試しに作ってみたいですね。