全開のブログではインデックスがある前提でインデックスを push モデルで更新する方法と、camel case への変換に関する Tips を書きました。
インデックスありきの話を書いたので、今回はそもそものインデックスを作るところのメモです。
具体的には、データが Azure の Blob や Cosmos DB にあってそれをインポートしてインデックスを作ろうって話です。
ハマりポイントが一点あり、それをメモしておきたかった次第です。
事前準備
インポートするのは以下のようなデータにしてます。データは、string と bool と int の型混在、あとはネストで値を持ってるデータを突っ込もうと思った程度でそれ以外は特に意味がない適当です。
[ { "id": "73a0ab73-64a7-4fe2-bd41-f2c4d05fabbb", "person": { "id": "cde2d9dc-0d47-4320-85d7-46e8e5a2a5a1", "firstName": "Noah", "lastName": "initial-data" }, "level": 22, "isWizard": true }, { "id": "0ae80271-6a95-4ac9-8aa6-73a27b3463ab", "person": { "id": "f6402297-e1df-400c-b835-74450250d93a", "firstName": "John", "lastName": "initial-data" }, "level": 69, "isWizard": true }, { "id": "73e2a2bc-1c4b-440c-9fc9-045031d35d9e", "person": { "id": "2b04c169-a7ec-402d-82a6-9f6f3fb3d28b", "firstName": "Taro", "lastName": "initial-data" }, "level": 63, "isWizard": true } ]
これを Blob のリソースを作っておいておきましょう(手順は省略)。
Blob の Container の パブリックアクセスレベルは プライベート で OK です。Cognitive Search がちゃんと接続してくれます。

※ 今回 Blob でやるのは、Blob でハマりポイントがあるからです。
インデックスの作成
SDK を 使って C# などでインデックスを作成することも可能ですが、インデックスのスキーマの設定を C# のコードで表現すると Attribute がごちゃごちゃとつくので、そのクラスを他のドメインと共有するならその部分が嫌な感じがします。
プロダクションの運用のために IaC 化するとかだとコード化できることが正義ですが、そうでない場合(調査とか検証用にサクッと作りたいとか)だとめんどいだけです。
そんなときは Azure Portal から GUI で既存のデータソースからデータをインポートして作成するのがお手軽なので、それをやっていきましょう。
Azure Portal から データをインポートしてインデックスを作成
Azure Portal で Cognitive Search のリソースを作ったら、概要 にある データのインポート をクリックします。

データソースで Azure BLOB ストレージ を選択します。ほかにインポートできるデータソースはここで選べるものです。ちなみにサンプルを選んで MS が用意してるサンプルデータからインデックスを作成することもできます。

データに接続します のタブ(翻訳が変...)では、先ほどデータを置いた Blob を指定しました。ほかの項目はよしなに設定です。

次は Cognitive Search の特徴的な機能で AI との連携に関するところですが、今回は使わないのでスルーして次に進みます。

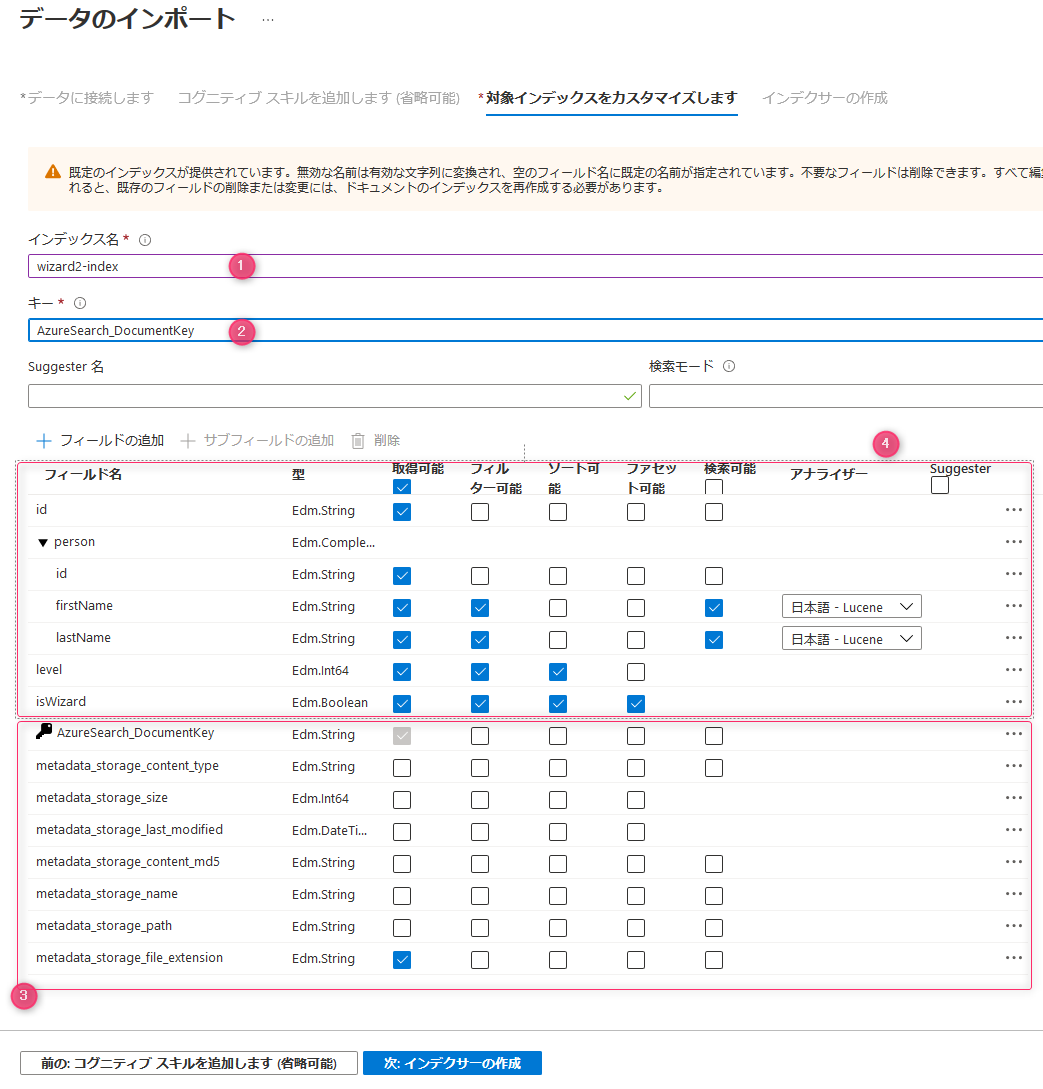
次が、インデックスをどう作るかの部分です。
- まずはインデックス名をそれっぽくしましょう(図①)。
- キーはBlob から作成すると、key は
AzureSearch_DocumentKeyという謎の値がセットされます (図②)。例えば Json のデータの id を キーにしたい場合は変更しましょう。 - Blob からデータをインポートすると Blob のメタデータも読み込んでくれます。不要な場合は削除します(図③)。
最後に書くフィールドに対して属性を定義します(図④)。属性でぱっとみわかりにくいのが フィルター可能 と 検索可能 です。フィルター可能はざっくり説明すると、対象の値を完全一致で検索する感じです。 検索可能 はフルテキスト検索をするかという意味です。そのためこれにチェックを入れるとパーサーを選択する必要があります。よくわからんという方は 日本語 - Lucene を選択して動作を確認するで問題ないです。
詳しくは公式ドキュメントを確認しましょう。
最後に インデクサーの作成 タブです。ここはサクッと 送信( Submit の翻訳が変...) のボタンをクリックしそうですがあかんです。まずはインデックスの名前をいい感じの名称に変えましょう。
そしてここが今回書きたかったポイントですが、Blob からインポートしたときは 詳細オプション を開いて Base-64 エンコード キー を見ましょう。このチェックがデフォルトでついているので、さきほど指定したキーがエンコードされてしまいます。キー に指定した値をそのまま使いたい場合は チェックを外します。
ちなみに Cosmos DB からインポートするときはこのチェックはデフォルトで外れています。

これで無事にインデックスが作成されます。
動作確認
インデックスが作成出来たら、概要 > インデックスのタブを開いて、作成したインデックスをクリックすると検索をお試しできます。

まとめ
キーの値が意図したものと違ったら Base64 encode されてるので注意!ってとこです。