Anthropic Research team のブログで "Building effective agents" という素敵なブログがあったので翻訳 (意訳) したメモです。
Building Effective AI Agents \ Anthropic
我々が2024年に取り組んでいた方向性・考え方がほぼ一緒で共感する部分が多かったので、その整理としてって感じでもあります。 Workflow や Agents の概念は基本的なことしか書かれてないですが、最も共感したのは、問題解決においてまずはシンプルに、必要に応じて複雑化していく考え方 (なんでも間でも Agents 使えばいいって話ではないとか、それはそもそも生成 AI 使うべきかにも通ずる)。実装でもフレームワークの利用よりもシンプルな実装からという基本的な考えが言及されているところです。
生成AIがブームになって新たな道が開けたせいか、2024年は目的と手段をはき違えて考えてしまってる場面に遭遇することが増えたなーと感じていましたが (未知のことが多いと仕方ないですけどね)、それを見直すための基本的な考え方が書かれていて素敵と思ったところです。
ということで、本題で以下より記事の意訳になります。
なお、冒頭は挨拶的なのだったので省略して "What are agents" から始めます。
- What are agents? (agents とは)
- Agents をいつ使うか (およびいつ使わないか)
- When and how to use frameworks (フレームワークをいつどのように使用するか)
- Building blocks, workflows, and agents
- Combining and customizing these patterns (これらのパターンを組み合わせてカスタマイズする)
- Summary
- Appendix 1: Agents in practice
- Appendix 2: Prompt engineering your tools
What are agents? (agents とは)
「agents」はいくつかの方法で定義できます。あるお客様は、agents を複雑なタスクを達成するためにさまざまなツールを使用して、長期間にわたって独立して動作する完全に自律的なシステムとして定義しています。また、事前定義された workflow に従う、より規範的な実装を説明するためにこの用語を使用するお客様もいます。 Anthropicでは、これらのバリエーションをすべてエージェントシステムとして分類していますが、workflow と agents の間には重要なアーキテクチャ上の違いがあります。
- Workflowsは、LLMと tool が事前定義されたコードパスを通じて調整されるシステムです。
- Agents は、LLMが独自のプロセスとツールの使用を動的に指示し、タスクを達成する方法を制御するシステムです。
以下では、両方のタイプのエージェント システムについて詳しく説明します。付録 1 ("Agents in Practice" (Agents の実践)) では、顧客がこれらの種類のシステムを使用することで特に価値を見出している 2 つの領域について説明します。
Agents をいつ使うか (およびいつ使わないか)
LLM でアプリケーションを構築する場合は、可能な限りシンプルなソリューションを見つけ、必要な場合にのみ複雑さを増すことをお勧めします。 これは、Agentic systems をまったく構築しないことを意味する場合があります。 Agentic systems は、多くの場合、タスクのパフォーマンスを向上させるためにレイテンシーとコストを犠牲にします。 このトレードオフがいつ理にかなっているかを検討する必要があります。
より複雑な処理が必要な場合は、workflow は明確に定義されたタスクに対して予測可能性と一貫性を提供しますが、柔軟性とモデル駆動型の意思決定が規模に応じて必要な場合は、agents の方が適しています。 ただし、多くのアプリケーションでは、検索とコンテキスト内の例を使用して単一の LLM 呼び出しを最適化するだけで十分です。
When and how to use frameworks (フレームワークをいつどのように使用するか)
Agentic systemsの実装を容易にするフレームワークは多数あります。
- LangChain の LangGraph ;
- Amazon Bedrock の AI Agent framework;
- Rivet, ドラッグアンドドロップGUI LLMワークフロービルダー;
- Vellum, 複雑なワークフローを構築およびテストするための別のGUIツール
これらのフレームワークは、LLMの呼び出し、ツールの定義と解析、呼び出しの連鎖などの標準的な低レベルのタスクを簡素化することで、簡単に開始できるようにします。 しかし、多くの場合、基になるプロンプトと応答をわかりにくくする抽象化の追加レイヤーが作成されるため、デバッグが難しくなります。 また、単純な設定で十分な場合に、複雑さを追加したくなる可能性があります。
開発者は、LLM API を直接使用することから始めることをお勧めします。 多くのパターンは数行のコードで実装できます。 フレームワークを使用する場合は、基になるコードを理解していることを確認してください。 内部の動作に関する誤った仮定は、エラーの一般的な原因です。
サンプル実装については、当社 (Anthropic)の cookbookを参照してください。
Building blocks, workflows, and agents
このセクションでは、実稼働環境で見られるエージェント システムの一般的なパターンについて説明します。 まず、基本的な構成要素である拡張 LLM から始めて、単純な構成ワークフローから自律エージェントまで、徐々に複雑さを増していきます。
Building block: The augmented LLM
agentic system の基本的な building block (構成要素) は、検索、ツール、メモリなどの拡張機能を備えた LLM です。現在のモデルは、独自の検索クエリの生成、適切なツールの選択、保持する情報の決定など、これらの機能を積極的に使用できます。
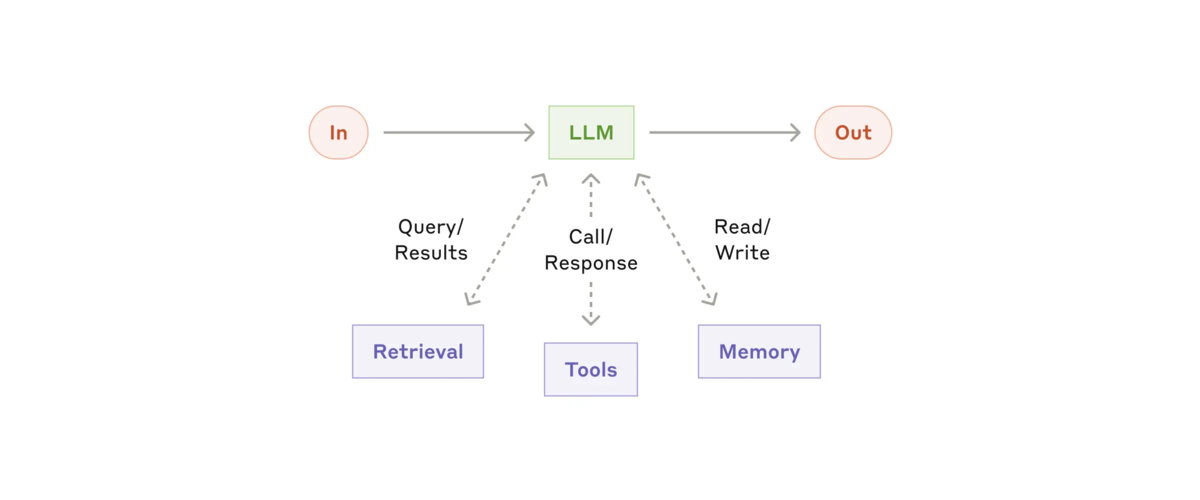 ※ The augmented LLM: https://www.anthropic.com/research/building-effective-agents より参照
※ The augmented LLM: https://www.anthropic.com/research/building-effective-agents より参照
実装の 2 つの重要な側面に重点を置くことをお勧めします。つまり、これらの機能を特定のユースケースに合わせて調整し、LLM に簡単で十分に文書化されたインターフェースを提供するようにすることです。 これらの拡張機能を実装する方法は多数ありますが、1 つの方法は、最近リリースされたModel Context Protocolを使用することです。これにより、開発者はシンプルなクライアント実装で、成長を続けるサードパーティ ツールのエコシステムと統合できます。
この投稿の残りの部分では、各 LLM 呼び出しがこれらの拡張機能にアクセスできると想定します。
Workflow: Prompt chaining
Prompt chaining (プロンプトの連鎖) は、タスクを一連のステップに分解し、各 LLM 呼び出しで前の呼び出しの出力を処理します。中間ステップにプログラムによるチェック (下の図の "Gate" を参照) を追加して、プロセスが順調に進んでいることを確認できます。
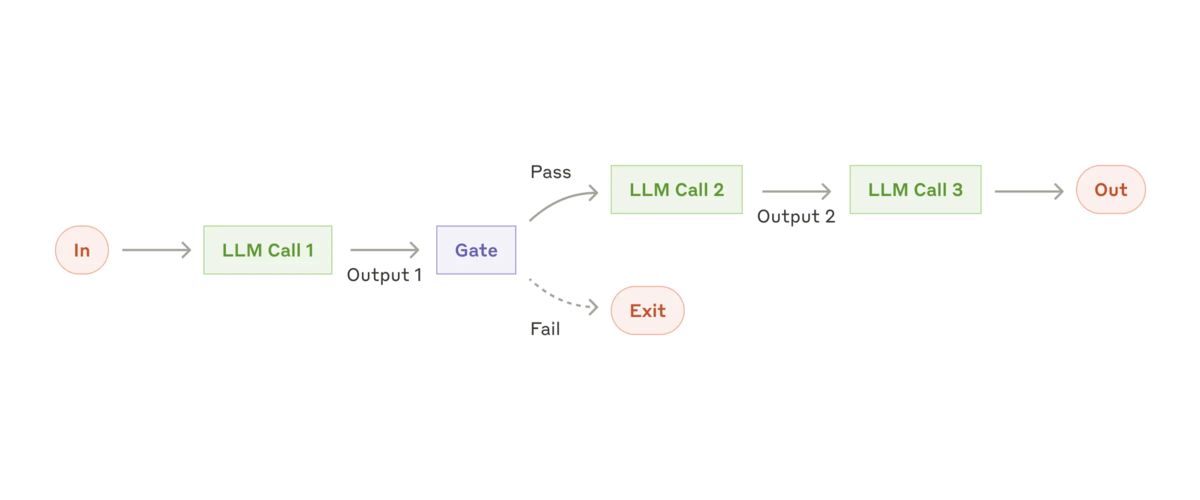 ※ The prompt chaining workflow: https://www.anthropic.com/research/building-effective-agents より参照
※ The prompt chaining workflow: https://www.anthropic.com/research/building-effective-agents より参照
この Workflow をいつ使うか: この Workflow は、タスクを固定サブタスクにかつきれいに分解できる状況に最適です。主なゴールは、各 LLM 呼び出しをより簡単なタスクにすることで、レイテンシを犠牲にして精度を高めることです。
Prompt chaining が役立つ例:
- マーケティングコピーを生成し、それを別の言語に翻訳する。
- ドキュメントのアウトラインを作成し、アウトラインが特定の基準を満たしていることを確認してから、アウトラインに基づいてドキュメントを作成する。
Workflow: Routing
Routing (ルーティング) は入力を分類し、それを専門的なフォローアップタスクに誘導します。この workflow により、関心を分離と、より専門的なプロンプトを構築できます。この workflow がないと、ある種の入力の最適化が他の入力のパフォーマンスに悪影響を与える可能性があります。
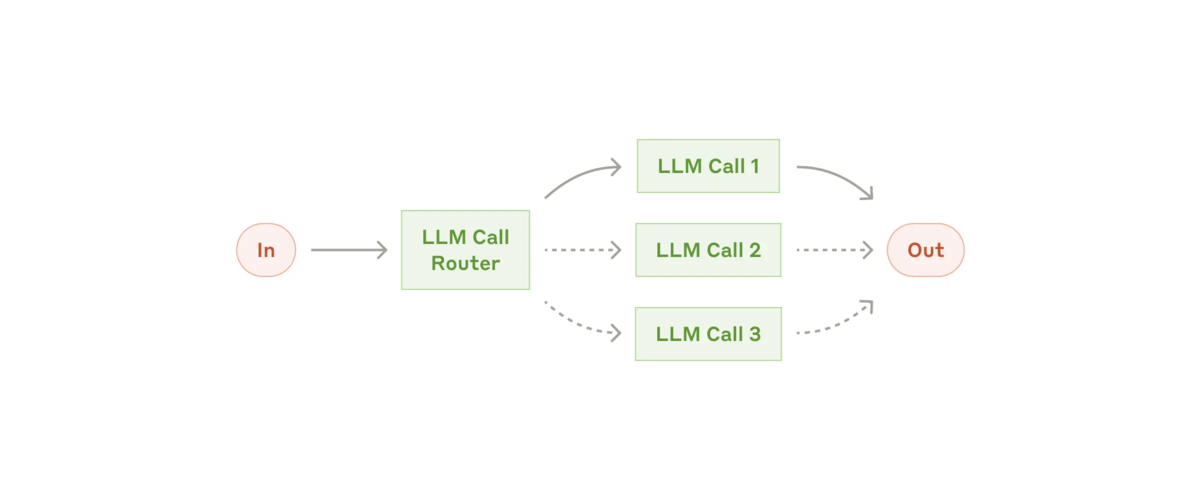 ※ The routing workflow: https://www.anthropic.com/research/building-effective-agents より参照
※ The routing workflow: https://www.anthropic.com/research/building-effective-agents より参照
この Workflow をいつ使うか: ルーティングは、個別に処理する方が適切な明確なカテゴリがあり、LLMまたはより従来の分類モデル/アルゴリズムによって分類を正確に処理できる複雑なタスクに適しています。
Routing が役立つ例:
- さまざまなタイプのカスタマーサービスの問い合わせ(一般的な質問、払い戻しのリクエスト、テクニカルサポート)を、さまざまなダウンストリームプロセス、プロンプト、およびツールに送る。
- 簡単/一般的な質問をClaude 3.5 Haikuなどの小さなモデルにルーティングし、難しい/珍しい質問をClaude 3.5 Sonnetなどのより機能の高いモデルにルーティングして、コストと速度を最適化する。
Workflow: Parallelization (並列化)
LLMは、タスクを同時に処理しその出力をプログラムで集約できる場合があります。このワークフローである並列化は、2つの主要なバリエーションで現れます。
- Sectioning: タスクを並行して実行される独立したサブタスクに分割します。
- Voting: 同じタスクを複数回実行して、さまざまな出力を取得します。
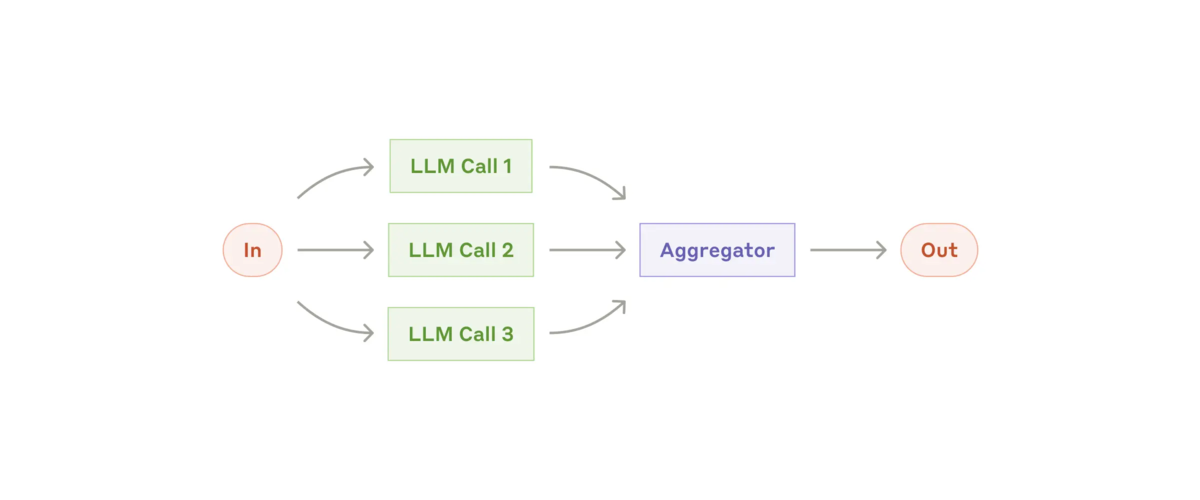 ※ The parallelization workflow: https://www.anthropic.com/research/building-effective-agents より参照
※ The parallelization workflow: https://www.anthropic.com/research/building-effective-agents より参照
この Workflow をいつ使うか: 並列化は、分割されたサブタスクを速度のために並列化できる場合、または信頼性の高い結果を得るために複数の視点または試行が必要な場合に効果的です。複数の考慮事項がある複雑なタスクの場合、LLMは一般に、各考慮事項が個別の LLM 呼び出しによって処理される場合にパフォーマンスが向上し、各特定の側面に焦点を当てることができます。
Parallelization が役立つ例:
- Sectioning
- 1 つのモデルインスタンスがユーザークエリを処理し、別のモデルインスタンスが不適切なコンテンツやリクエストをスクリーニングするガードレールを実装します。この方法は、ガードレールとコアのレスポンスの両方を同じ LLM 呼び出しで処理するよりもパフォーマンスが向上する傾向があります。
- LLMのパフォーマンスを評価するための自動化された評価。各LLM呼び出しは、特定のプロンプトに対するモデルのパフォーマンスのさまざまな側面を評価します。
- Voting
- 脆弱性がないかコードをレビューします。いくつかの異なるプロンプトがコードをレビューし、問題が見つかった場合はフラグを立てます。
- 特定のコンテンツが不適切かどうかを評価します。複数のプロンプトがさまざまな側面を評価するか、誤検知と誤検知のバランスをとるために異なる投票しきい値を必要とします。
Workflow: Orchestrator-workers
Orchestrator-workers の workflow では、中心となる LLM がタスクを動的に分解し、worker LLM に委任して、その結果を合成 (synthesize)します。
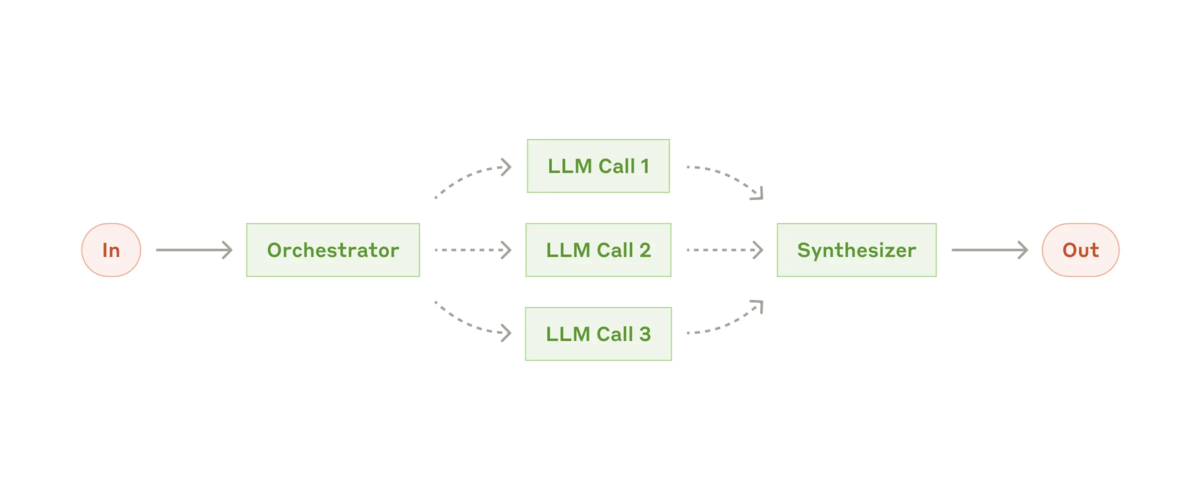 ※ The orchestrator-workers workflow: https://www.anthropic.com/research/building-effective-agents より参照
※ The orchestrator-workers workflow: https://www.anthropic.com/research/building-effective-agents より参照
この Workflow をいつ使うか: この workflow は、必要なサブタスクを予測できない複雑なタスクに適しています (たとえば、コーディングでは、変更する必要があるファイルの数と各ファイルの変更の性質は、タスクによって異なります)。トポロジ的には似ていますが、並列化との主な違いは柔軟性です。サブタスクは事前に定義されておらず、特定の入力に基づいてオーケストレーターによって決定されます。
Orchestrator-workers が役立つ例:
- 毎回複数のファイルに複雑な変更を加えるようなコーディングのタスク
- 関連する可能性のある情報について、複数のソースから情報を収集して分析する検索タスク
Workflow: Evaluator-optimizer
Evaluator-optimizer では、1つのLLM呼び出しが応答を生成し、別のLLM呼び出しがループで評価とフィードバックを提供します。
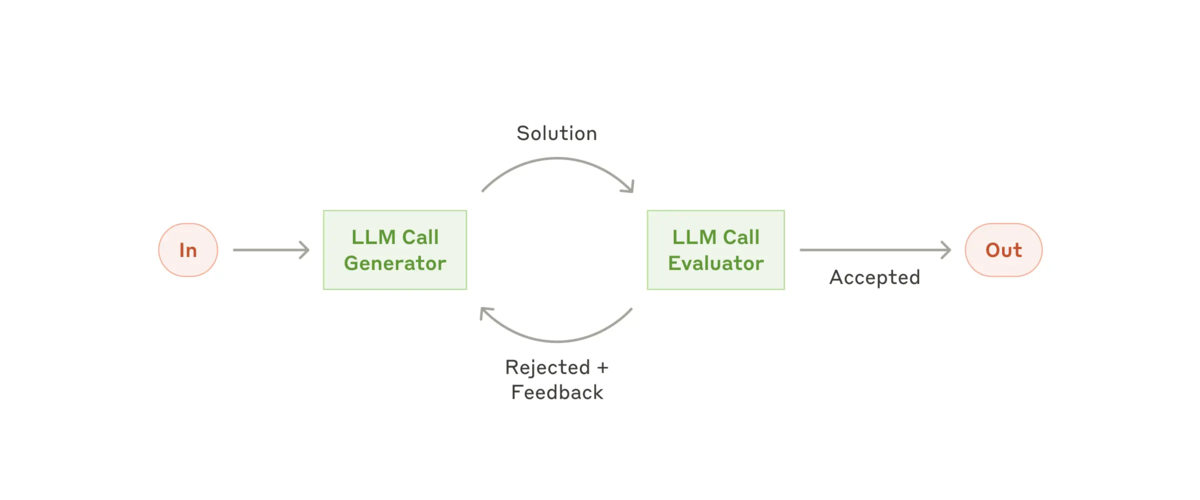 ※ The evaluator-optimizer workflow: https://www.anthropic.com/research/building-effective-agents より参照
※ The evaluator-optimizer workflow: https://www.anthropic.com/research/building-effective-agents より参照
この Workflow をいつ使うか: このワークフローは、評価基準が明確で、反復的な改良によって測定可能な価値が得られる場合に特に効果的です。適合性が高いことを示す 2 つの兆候は、まず、人間がフィードバックを明確に表現すると LLM の応答が明らかに改善されること、そして 2 番目に、LLM がそのようなフィードバックを提供できることです。これは、人間のライターが洗練された文書を作成するときに行う反復的な執筆プロセスに似ています。
Evaluator-optimizer が役立つ例:
- 翻訳用の LLM が最初に捉えられない可能性のあるニュアンスがあるが、evaluator (評価者) 用の LLM が有用な批評を提供できる文学翻訳。
- 包括的な情報を収集するために複数回の検索と分析を必要とする複雑な検索タスク。evaluator (評価者) は、さらなる検索が必要かどうかを決定します。
Agents
LLM が複雑な入力を理解し、推論と計画を行い、ツールを信頼性高く使用し、エラーから回復するといった主要な機能において成熟するにつれて、Agents が製品として登場し始めています。エージェントは、人間のユーザーからのコマンドまたはユーザーとの対話的な話し合いによって作業を開始します。 タスクが明確になると、agents は独立して計画と操作を行い、場合によっては人間に戻ってさらなる情報や判断を求めます。 実行中、agents がツール呼び出し結果やコード実行などの各ステップでその "Environment" から "ground truth" (雑にいうと正しいデータ)を取得し、進行状況を評価することが非常に重要です。 Agents はチェックポイントや障害に遭遇したときに、人間からのフィードバックを得るために一時停止できます。
タスクは完了時に終了することがよくありますが、制御を維持するために停止条件 (反復の最大回数など) を含めることもよくあります。
エージェントは高度なタスクを処理できますが、その実装は多くの場合簡単です。エージェントは通常、環境フィードバックに基づくツールをループで使用する LLM にすぎません。したがって、ツールセットとそのドキュメントを明確かつ慎重に設計することが重要です。ツール開発のベスト プラクティスについては、付録 2 ("Prompt Engineering your Tools") で詳しく説明します。
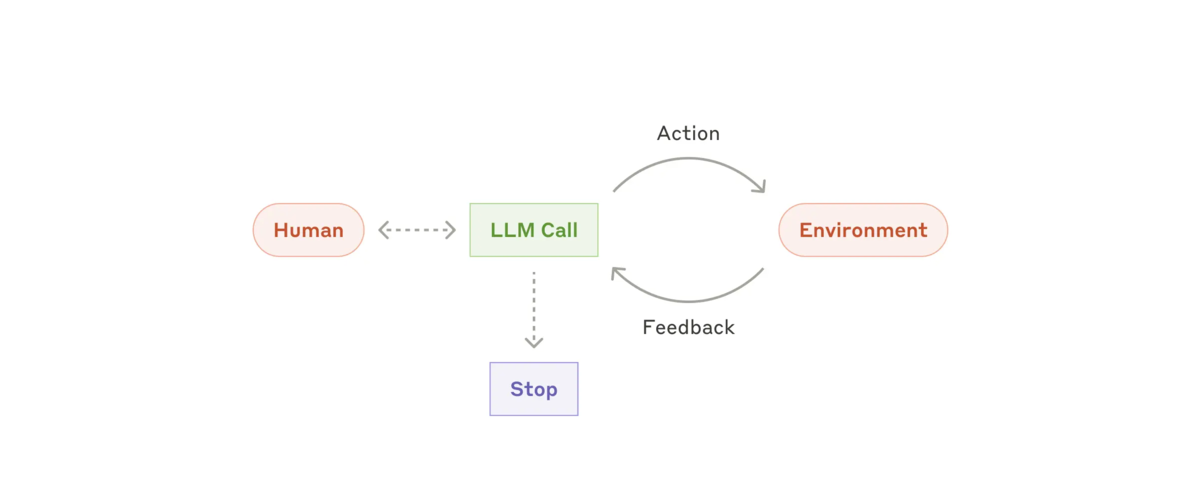 ※ Autonomous agent: https://www.anthropic.com/research/building-effective-agents より参照
※ Autonomous agent: https://www.anthropic.com/research/building-effective-agents より参照
この Workflow をいつ使うか: Agents は、必要なステップ数を予測することが困難または不可能で、固定パスをハードコードできない open-ended の問題に使用できます。LLM は潜在的に多くのターンにわたって動作するため、その意思決定にはある程度の信頼が必要です。Agents の自律性により、信頼できる環境でタスクをスケーリングするのに最適です。
Agents の自律性は、コストが高くなり、エラーが複雑化する可能性を意味します。適切なガードレールとともに、サンドボックス環境で広範囲にテストすることをお勧めします。
Agents が役立つ例:
以下の例は、当社 (Anthropic) 独自の実装からのものです。
- タスクの説明に基づいて多数のファイルを編集する SWE-bench tasksを解決するcoding Agent。
- Claude がコンピュータを使用してタスクを実行する "computer use" リファレンス実装。
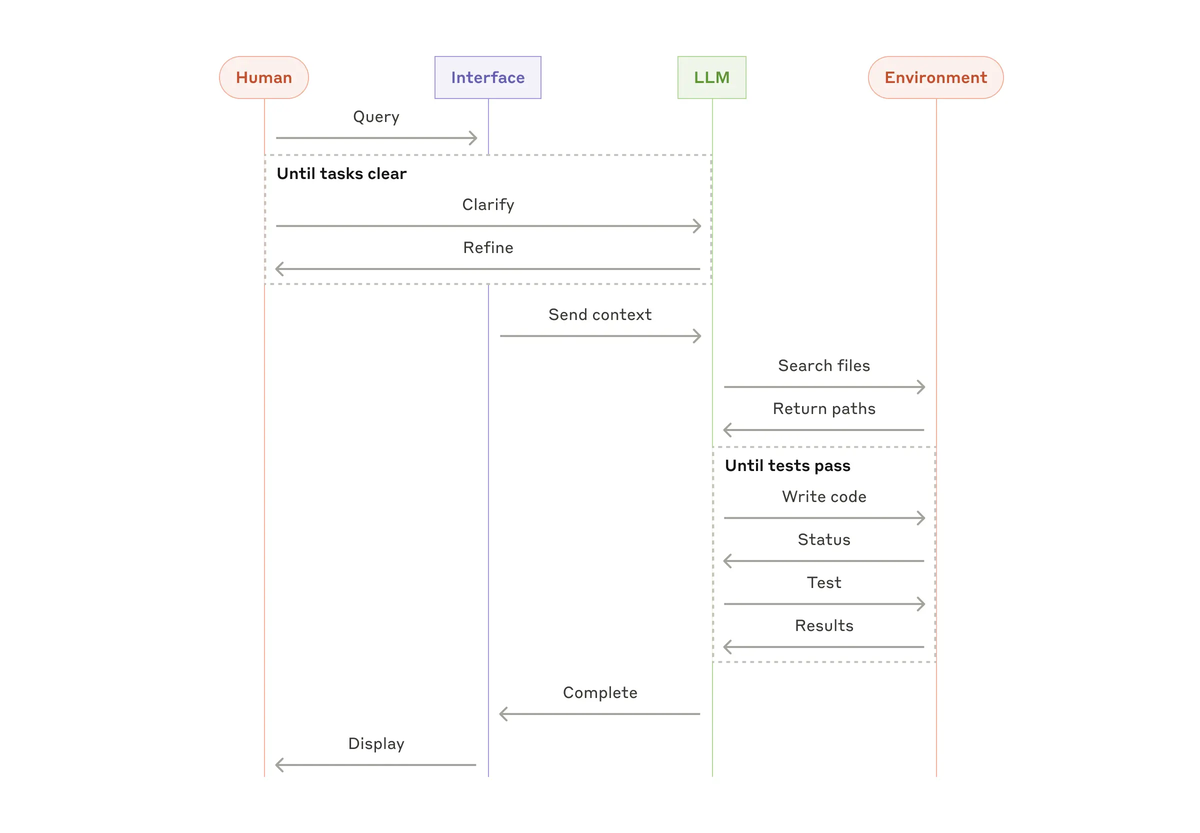 ※ High-level flow of a coding agent: https://www.anthropic.com/research/building-effective-agents より参照
※ High-level flow of a coding agent: https://www.anthropic.com/research/building-effective-agents より参照
Combining and customizing these patterns (これらのパターンを組み合わせてカスタマイズする)
これらの構成要素は規定的なものではありません。開発者がさまざまなユース ケースに合わせて形を整えたり組み合わせたりできる一般的なパターンです。他の LLM 機能と同様に、成功の鍵はパフォーマンスを測定し、実装を繰り返すことです。繰り返しますが、複雑さの追加は、明らかに結果が改善される場合にのみ検討する必要があります。
Summary
LLM 分野で成功するには、最も洗練されたシステムを構築することが大切ではありません。ニーズに合った適切なシステムを構築することが大切です。 シンプルなプロンプトから始めて、包括的な評価で最適化し、シンプルなソリューションが不十分な場合にのみ、マルチステップの Agentic system を追加します。
Agents を実装する際、私たちは次の 3 つの基本原則に従うようにしています。
- Agents の設計ではシンプルさを維持します。
- Agents の計画手順を明示的に表示することで透明性を優先します。
- 徹底したツールのドキュメント化とテストを通じて、agent-computer interfaces (ACI) を慎重に作成します。
フレームワークはすぐに開始するのに役立ちますが、実稼働に移行する際には、抽象化レイヤーを減らして基本的なコンポーネントで構築することを躊躇しないでください。これらの原則に従うことで、強力なだけでなく、信頼性が高く、保守しやすく、ユーザーから信頼される Agents を作成できます。
Appendix 1: Agents in practice
お客様との協力により、上で説明したパターンの実用的な価値を実証する AI エージェントの特に有望な 2 つのアプリケーションが明らかになりました。どちらのアプリケーションも、会話とアクションの両方を必要とし、明確な成功基準を持ち、フィードバックループを有効にし、意味のある人間による監視を統合するタスクに Agents が最大の価値を追加する方法を示しています。
A. Customer support
カスタマー サポートでは、使い慣れたチャットボット インターフェイスとツール統合による強化された機能を組み合わせます。これは、次のような理由から、よりオープンエンドなエージェントに最適です。
- サポートのやり取りは、外部の情報やアクションへのアクセスを必要としながら、会話の流れに自然に従います。
- ツールを統合して、顧客データ、注文履歴、ナレッジベースの記事を取得できます。
- 払い戻しやチケットの更新などのアクションはプログラムで処理できます。
- 成功 (問い合わせの解決) は、ユーザー定義の解像度を通じて明確に測定できます。
いくつかの企業は、成功した解決に対してのみ料金を請求する使用量ベースの価格設定モデルを通じてこのアプローチの実行可能性を実証し、Agents の有効性の信頼度を示しています。
B. Coding agents
ソフトウェア開発分野では、コード補完から自律的な問題解決まで機能が進化し、LLM 機能の驚くべき可能性が示されています。エージェントが特に効果的な理由は次のとおりです。
- コード ソリューションは自動テストを通じて検証可能。
- エージェントはテスト結果をフィードバックとして使用してソリューションを反復できる。
- 問題領域は明確に定義され、構造化されている。
- 出力の品質を客観的に測定可能
弊社 (Anthropic)の実装では、Agents は Pull Request の説明のみに基づいて、SWE-bench Verified ベンチマークで実際の GitHub の問題を解決できるようになりました。ただし、自動テストは機能の検証に役立ちますが、ソリューションがより広範なシステム要件に適合していることを確認するには、人間によるレビューが依然として重要です。
Appendix 2: Prompt engineering your tools
どのような Agentic system を構築する場合でも、ツールは agents の重要な部分になります。ツールを使用すると、Claude は API で外部サービスや API の正確な構造と定義を指定して、それらと対話できます。Claude が応答するときに、ツールを呼び出す予定がある場合は、API 応答にツール使用ブロックが含まれます。ツールの定義と仕様には、全体的なプロンプトと同じくらいプロンプト エンジニアリングの注意を払う必要があります。この簡単な付録では、ツールをプロンプト エンジニアリングする方法について説明します。
同じアクションを指定するには、多くの場合、複数の方法があります。たとえば、diff を記述するか、ファイル全体を書き直すことで、ファイルの編集を指定できます。構造化された出力の場合は、マークダウン内または JSON 内でコードを返すことができます。 ソフトウェア エンジニアリングでは、このような違いは表面的なものであり、一方から他方へロスなく変換できます。 ただし、一部の形式は、LLM にとって他の形式よりも記述がはるかに困難です。 diff を記述するには、新しいコードが記述される前に、チャンク ヘッダーで変更される行数を知る必要があります。JSON 内でコードを記述するには (マークダウンと比較して)、改行と引用符の追加のエスケープが必要です。
ツールの形式を決定するための提案は次のとおりです。
- モデルが行き詰まる前に、モデルに「考える」のに十分なトークンを与えます。
- モデルがインターネット上のテキストで自然に発生するのを見た形式に近い形式を維持します。
- 数千行のコードを正確にカウントしたり、書き込んだコードを文字列エスケープしたりするなど、フォーマットの「オーバーヘッド」がないことを確認します。
経験則の 1 つは、human-computer interfaces (HCI) にどれだけの労力が費やされているかを考え、優れた agent-computer interface (ACI) の作成に同じだけの労力を投資する計画を立てることです。その方法について、いくつか考えてみましょう。
- モデルの立場に立って考えてみましょう。説明とパラメータから、このツールの使い方は明らかでしょうか、それとも慎重に考える必要があるでしょうか。そうであれば、おそらくモデルにも当てはまるでしょう。優れたツール定義には、使用例、エッジケース、入力形式の要件、および他のツールとの明確な境界が含まれることがよくあります。
- パラメータ名や説明を変更して、よりわかりやすくするにはどうすればよいでしょうか。これは、チームのジュニア開発者向けに優れたドキュメント文字列を記述することだと考えてください。これは、類似のツールを多数使用する場合に特に重要です。
- モデルがツールをどのように使用するかをテストします。workbenchで多くのサンプル入力を実行し、モデルがどのような間違いを犯すかを確認し、反復します。
- ツールに対してPoka-yokeします。引数を変更して、間違いを起こしにくくします。
SWE-bench 用のエージェントを構築する際、実際には全体的なプロンプトよりもツールの最適化に多くの時間を費やしました。たとえば、エージェントがルート ディレクトリから移動した後、モデルは相対ファイルパスを使用するツールでエラーを起こすことがわかりました。これを修正するために、ツールを常に絶対ファイルパスを要求するように変更したところ、モデルはこの方法を完璧に使用しました。