幅広いデータソースを Markdown に変換してくれる Microsoft の OSS: MarkItDown を試してみます。
使った感想
とりあえず最初に書いておきます。
- すごーくシンプルなファイルに対してはシンプルな実装で読み取りできるので、いいなと。
- 部分的にでも Azure の Document Intelligence にかわる要素があればと思ったけど、私が絡んでるお仕事での活用は現段階では精度的に厳しい。
- なにが厳しかったかを、後述のサンプル実装で書いていきます。
MarkItDown の概要
Micrososft の OSS でいろんなデータソースを読んでマークダウンに変えてくれるライブラリ。 対象ファイルに Excel とか Word も入ってるのがうれしい。画像やオーディオもいけるようですごくよさそう。
- PDF (.pdf)
- PowerPoint (.pptx)
- Word (.docx)
- Excel (.xlsx)
- Images (EXIF metadata, and OCR)
- Audio (EXIF metadata, and speech transcription)
- HTML (special handling of Wikipedia, etc.)
- Various other text-based formats (csv, json, xml, etc.)
といってもゴリゴリに新しい要素があるってほどではなく、Python の各種ライブラリをまとめて使いやすくしたって感じに見えてます。
Python で試す準備
今回私が試すのに pip install で必要なのは以下3つ。
python-dotenv markitdown onepai
PDF を試す
PDF も余裕で読み込めるだろうと思っているが...。
コードの実装はシンプルでこんな感じ。
from markitdown import MarkItDown md = MarkItDown() result = md.convert("sample_files/sample3.pdf") print(result.text_content)
結論からいうと、シンプルに文字が並んでる PDF しか読めない印象。
2段組の PDF
2段組みを理解できずぐちゃぐちゃに...やはり段組みは LLM/SLM の力がないと厳しかー。
図多めの PDF
文字を何とか読み取ってくれるけど、ほかのライブラリ同様に図としての構造は理解しないので厳しい。
pptx を試す
15ページ中ほとんどがシンプルに構成された文字と、1ページだけがっつり図の pptx を試してみます。 コードは PDF の時と変わらんので省略。
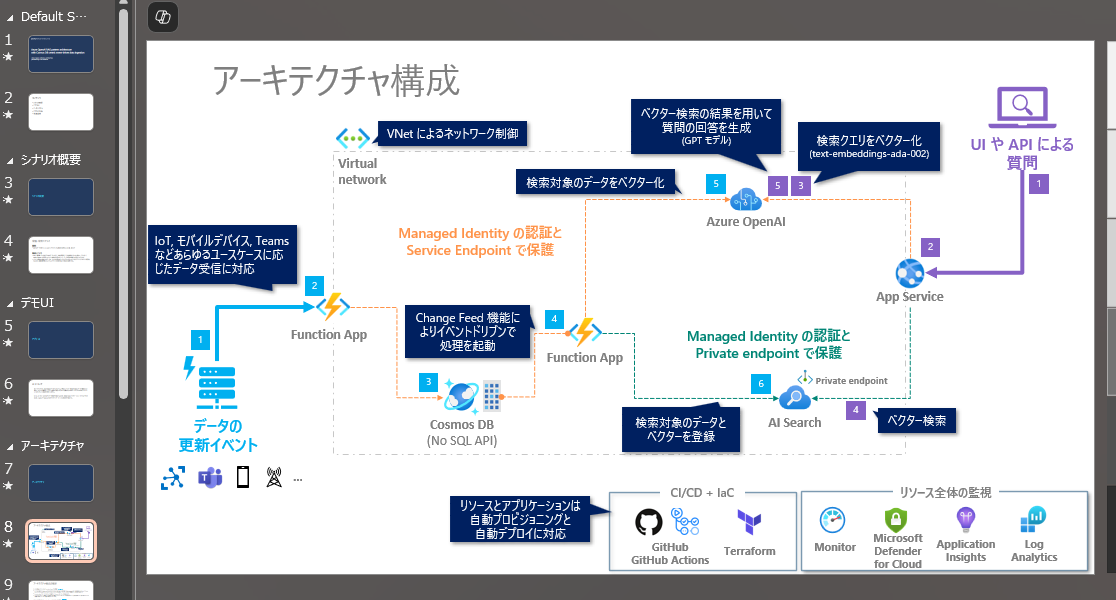
- 文字列はある程度読み込めたけど、箇条書きで書かれてる文字もプレーンなテキストで出力されてるので、Markdown で出力できてないという意味で精度は低い。
- 図 (というか pptx 内でのオブジェクト) は全然だめっぽい。まー図だからそうだよね。
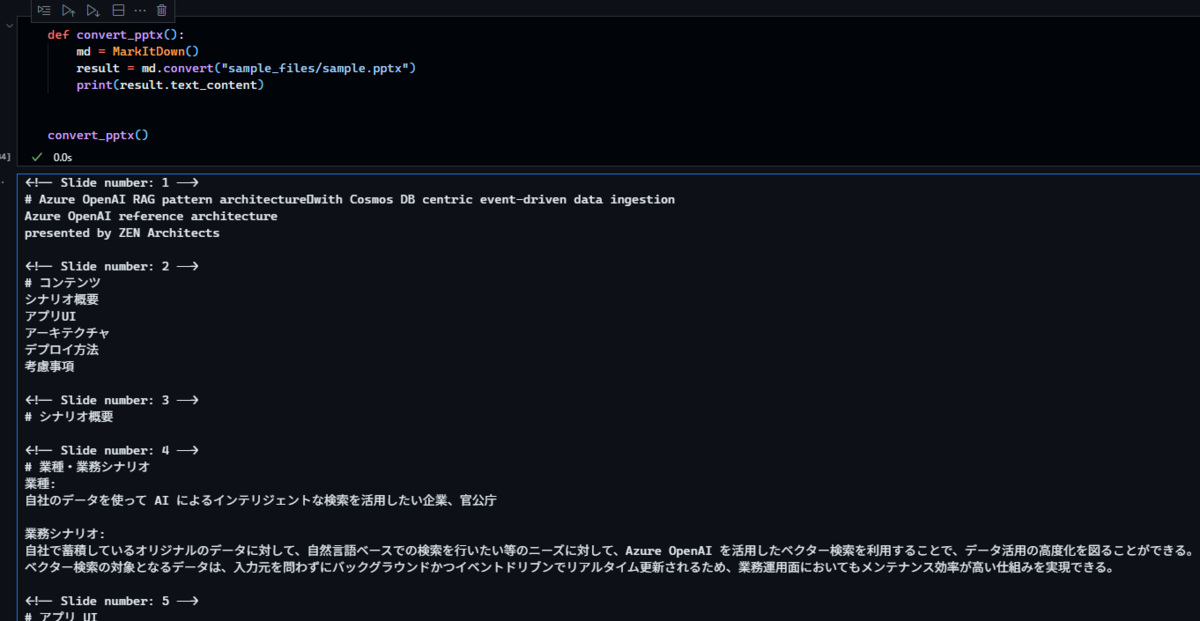
Excel を試す
こちらも実装は PDF の時と変わらんので省略。 CSV くらいシンプルな表なら読めるけど、以下図のような Excel だともう壊滅する。
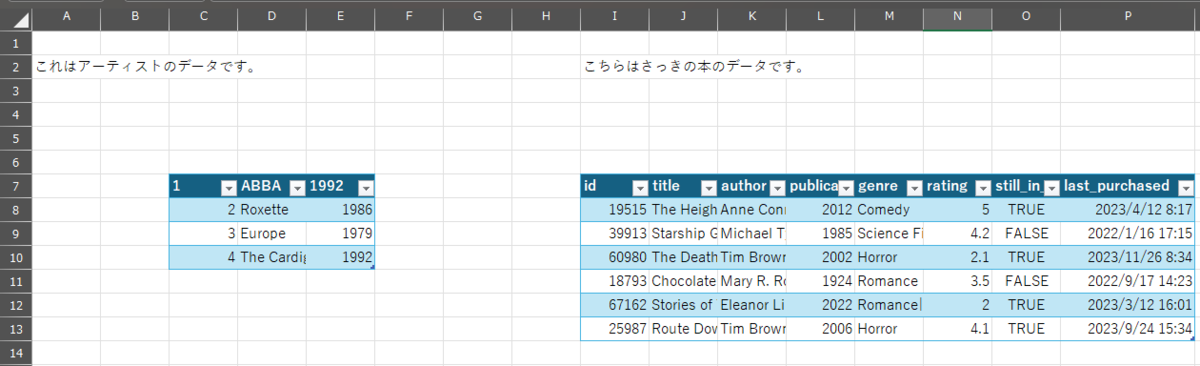
こんな感じ。まー Excel はいつでもつらいのだけれども。
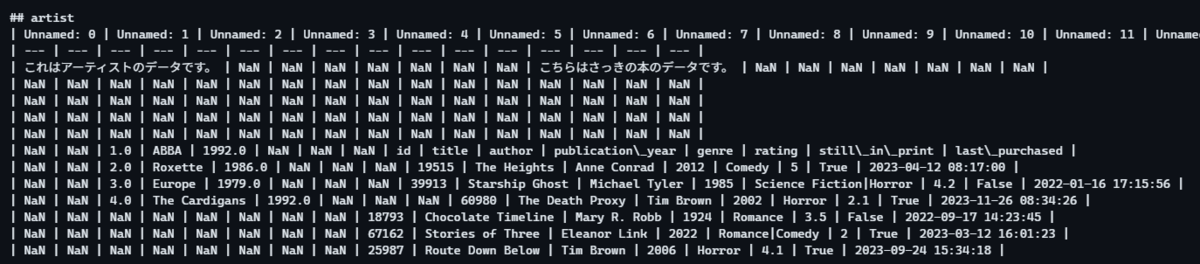
画像の解析
- 現時点で画像でサポートしてる拡張子は、".jpg", ".jpeg", ".png" のみ。
- 画像を読み込むには LLM が必須なので、
.envのファイル作って以下の感じで構成。
AOAI_ENDPOINT=xxx AOAI_API_KEY =xxxx AOAI_API_VERSION=2024-10-21 AOAI_DEPLOYMENT_CHAT=xxxxx
画像の解析: とりあえず動かす
Azure OpenAI の LLM を使ってこんな感じで動かしてみる。
import os from dotenv import load_dotenv from markitdown import MarkItDown from openai import AzureOpenAI load_dotenv() aoai_client = AzureOpenAI( azure_endpoint=os.environ['AOAI_ENDPOINT'], api_key=os.environ['AOAI_API_KEY'], api_version=os.environ['AOAI_API_VERSION'] ) markitdown = MarkItDown( mlm_client=aoai_client, mlm_model=os.environ["AOAI_DEPLOYMENT_CHAT"] ) result = markitdown.convert("./sample_files/autogen.jpg") print(result.text_content)
MarkItDown の中のテスト用に含まれてた Autogen の概要的な画像を読み込ませたが、いまいち。それはプロンプトの指定が以下のようにシンプルになっていたせいかなぁ。
MLM Prompt: Write a detailed caption for this image.
画像の解析: プロンプトをカスタマイズする
プロンプトはカスタマイズできるかなと思ってソースをみたらあったので変えてみる。
以下のように convert() の引数に mlm_prompt を追加すれば OK。「画像に書かれている内容を OCR のようにすべて読み込んでください」と指示してみる。
result = markitdown.convert(
"./sample_files/autogen.jpg",
mlm_prompt="画像に書かれている内容の markdown で構造化して出力して"
)
え...だめなんだ。。。
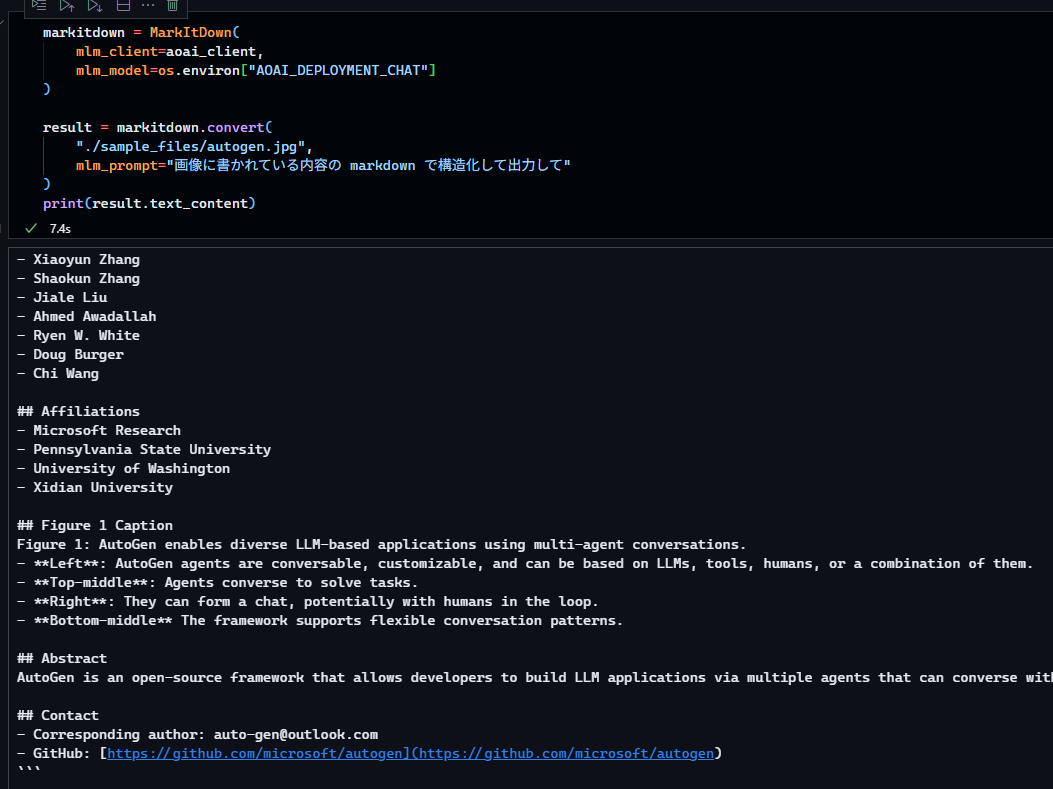
じゃー次はprompt を「画像に書かれている内容の markdown で構造化して出力して」にしてもう一度実行してみると、それっぽくでた。
これだと、GPT-4o とかに普通になげるので十分ではという印象だけど、音声とか
さいごに
- 私が絡んでるお仕事のデータソース、古の時代から錬成された Excel や Word や PDF ですら単純なフォーマットのものはほとんどないので現時点では厳しい。