Microsoft Build 2022 に合わせて Form Recognizer にいくつかのアップデートがありました。
この時期のあるあるとして、公式ドキュメント の日本語は翻訳されておらず古い状態になってるので、英語のドキュメントを見る必要がある時期ですね。
ということで自分の備忘録として書いていきます。
- Layout モデルで paragraphs や role の抽出
- ページを跨いだテーブル (表) の読み取り
- Invoice モデルの更新
- Read (OCR) で Microsoft Office のファイルと HTML のサポート
- Business card (名刺) モデルの更新
- ID (身分証明書) モデルの更新
- まとめ
Layout モデルで paragraphs や role の抽出
日本語の対応は:
- 手書き: X
- 手書きじゃない文字: 〇
paragraphs は、ここでは段落という翻訳というよりは、テキストブロックって感じでしょうか。青い枠で抽出されてる部分のことです。

(ネットから勝手に拝借させていただいた) 以下の 画像 を試しましたが、悪くないです♪

以前からテーブルデータを読み取る機能もあるので、上部中央にあるテーブルも普通に読み取れてます。(いや...一部読み取れてないですが、私が抽出した画像が荒かったので無理だった感じです。。。)
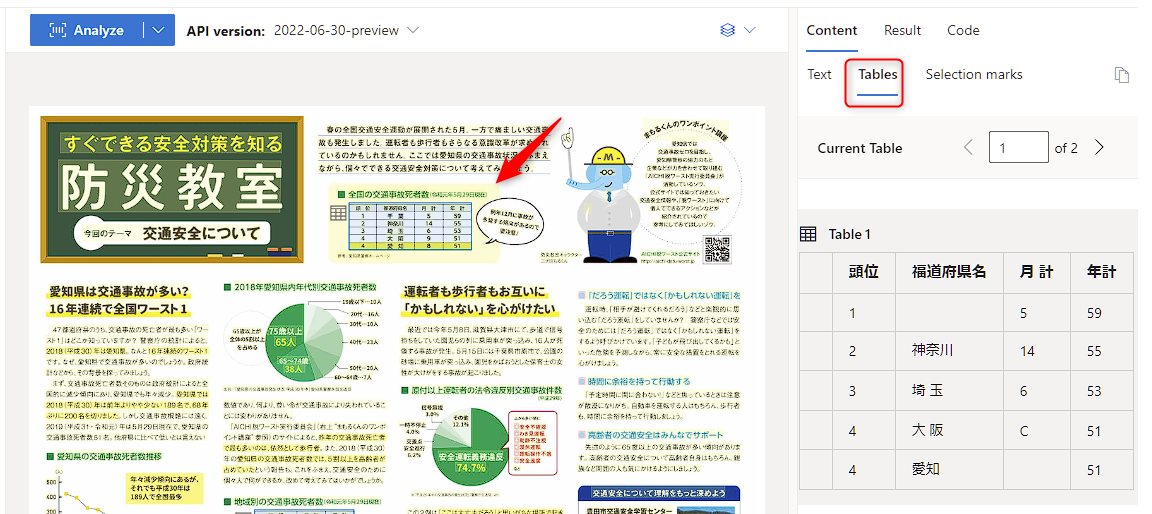
ページを跨いだテーブル (表) の読み取り
前提知識として From Recognizer では、前述の Layout モデルのような学習済みのモデルを使ってフォームから情報を抽出することもできます。また、抽出したいドキュメントを学習データとして独自に学習させ、最適なカスタムモデルを作ることも可能です。
で、この機能はカスタムモデルの中の カスタムニューラルモデル の話ですが、例えば1ページ目と2ページ目で表がまたがってるドキュメントを1つのテーブルとして認識させることができるようになりました。
カスタムモデルなので、学習データを用意して学習させることでできるようになります。
カスタムニューラルモデルは、2022年6月時点では英語のみの対応です。いい感じになったらほかの言語も増やす方針でがんばってるパターンですね。
Invoice モデルの更新
前提知識として From Recognizer では、汎用的なモデルとして Layout モデルと General document モデルと Read モデルがあります。この汎用的なモデルとは別に特定のフォームに特化して学習済みのモデルがあります。これらを「Prebuilt models」(事前構築済みモデルと翻訳されてます) といい、現在は、W-2 (アメリカの源泉徴収のフォーム)、請求書、レシート、身分証明書、名刺のモデルがあります。
その中で Invoice モデル (請求書モデル) に利用できる言語の5つ追加されました。日本語は対応してませんので、追加された言語はリンクを張るだけにしておきます。
あとは、General Document モデルで読み取ることができていた情報の一部が Layout モデルでもオプションとして出力できるようになりましたが...もちろん日本語対応してないです。
Read (OCR) で Microsoft Office のファイルと HTML のサポート
Read (OCR 機能の API) は、JPEG/JPG、PNG、BMP、TIFF、PDF を読むことができました。
今回新たに Word, Excel, PowerPoint と HTML のファイルを読み取ることができるようになりました。Read は元々日本語対応済みだったので利用できるはずですが、どの程度の精度ですかねー。
Form Recognizer Studio ではまだ Word とか試せなかったので、SDK でやる感じかな...
Business card (名刺) モデルの更新
Business card (名刺) モデルも Prebuild モデルのひとつですが、これに日本語が加わりました。なんか大きなリクエストでもあったんですかねー。
まぁ、名刺持ってないので試してないんですが。
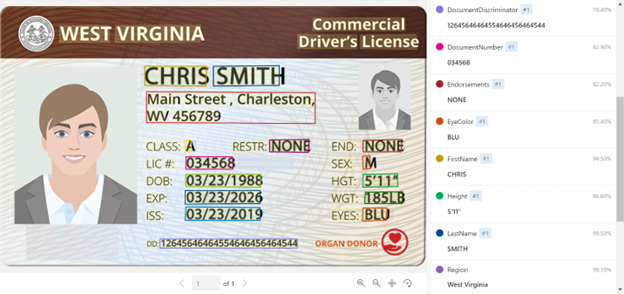
ID (身分証明書) モデルの更新
アメリカの運転免許証と国際パスポートから情報を読み取る Prebuild モデルです。今回追加されたのは、アメリカの運転免許証で読み取れる情報が増えて、目の色や髪の色などが増えました*1。ってか日本とアメリカで免許証に載ってる情報が全然違ってびっくりです。
まとめ
余談その1ですが、英語で FUJITSU の事例が出てましたね。
余談その2で、Microsoft Learn に Form Recognizer の2コンテンツがあります。以下のリンクのコンテンツはちょっと前からあるコンテンツで日本語版もあり基本的な内容がまとまってるので、最新情報が有無にかかわらず学べる印象です。
ということでちょいちょい進化している Form Recognizer に今後も注目していきたいです。
*1:具体的には、DateOfIssue, Height, Weight, EyeColor, HairColor, DocumentDiscriminator