Form Recognizer は、v2.1 preview 3 のアップデートで実用的に使えるじゃないかってくらいに感じたので、改めて機能や更新内容をメモしてみます。
Form Recognizer とは
ざっくり機能を説明すると、請求書やレシートといったドキュメントからデータを読み取ることができるサービスです。大きく3つの機能があります。
- Layout API: 日本語対応済み。様々なフォームのドキュメントから、テキストやテーブルなどを構造を読み取ることができます。
- カスタムモデル: 日本語対応済み。フォームにラベル付けをして機械学習してモデルを作ることで、より複雑なフォームの分析ができるようにするサービス。フォームの学習データは5つから始めることができるのでお手軽に、かつ、いい精度の分析が十分に期待できる(個人的な肌感ですが)。
- Prebuilt モデル (事前構築済みモデル) : Prebuilt モデルとは Microsoft が作った機械学習のモデルですが、特定のフォーム専用に作られたモデルを使ってデータを抽出します。4つは以下で、主に英語の対応のみです。
- 請求書
- レシート
- 名刺
- ID (パスポートや免許証)
最近のアップデート
細かいことは 公式ドキュメントの What's new を読むとして、ざっくりアップデートを要約します。
※ 2021/3/15 に英語のドキュメントが更新されたため日本語のドキュメントは翻訳が追いついておらず古いです。しばらくの間は英語のドキュメントを見るのが無難です。
2020年11月のアップデート
Form Recognizer v2.1 public preview 2 のリリースに基づくアップデート情報になります。
- Layout API とカスタムモデルで日本語サポート
- Prebuilt の Invoice モデルの機能が強化
- テーブル抽出の機能が強化され、結合された列、行、境界線を含む複雑なテーブルなどからのデータ抽出が可能に。
2021年3月 (Microsoft Ignite)
3/15 より v2.1 public preview 3 が気軽に試せるようになりました。このバージョンで更新された機能の情報になります。Ignite の予告通り 3/15 に英語のドキュメントはアップデートがかかりました。日本語はそのうち翻訳されるでしょう。
- Layout API とCustom Models それぞれ73言語に対応(今回66言語増えた)
- Prebuilt モデルに ID モデルが新規追加: パスポートやアメリカの免許証から情報を取得できる Prebuilt の API が増えた。
- Prebuilt の Invoice モデルでフォーム内にあるテーブルの項目が取得できるようになった。
- Prebuilt の Receipt モデルで特に明細の抽出が大幅に改善
- テキストの行の並び順を視点できるようになった(こちらを見るとイメージがつきます)
API のバージョン
前述でさらっと触れてますが一応整理しておきましょう。
- v2.0: 2020年6月 GA したバージョン。
- ついこないだまでは v2.1 public preview 2 が最新でしたが、v2.1 public preview 3 が2021年3月15日に利用できるようになりました。 このブログで紹介した新しい機能を利用するにはこの API を使う必要があります。
Form Recognizer を試す準備
オープンソースで Web 上にデプロイされており Free で使える Form Recognizer Tool を設定することで簡易に Form Recognizer を試すことができます。
設定方法を書こうと思ったら長くなったので、こちらのブログにまとめました。
Layout API とカスタムモデルを使った所感
自分の請求書やネット上に落ちてるサンプルの請求書を Layout API で分析かけてみたんですが、完ぺきに取得できました。あまり複雑なフォームは持ってないのでどんだけ複雑のいけるのかってのは試してませんが、私が普段使ってるものはばっちりだったという結果だけ書いておきます。
完ぺきに分析できたのでカスタムモデルを使う理由がなくて日本語のは試せてません。(英語の請求書はサンプルがたくさんあるので試しましたが)
ちなみに Layout API とカスタムモデルをサクッと試す方法も前述でもリンクをはった同じブログに書いてます。
Prebuilt の ID を試す
Pre-built の ID service は、OCR の機能によってパスポートや免許証から情報を取得するものです。免許証は "U.S. Driver's Licenses (all 50 states and D.C.)" と限定されてますが、パスポートは日本のパスポートでもほぼ英語で書かれてるからいけるんじゃね?と思って試してみました。
試す手順はこんな感じです。
- https://fott-preview.azurewebsites.net/ を開いてセットアップします(セットアップ方法は前回のブログのここに詳しく書いてます)。
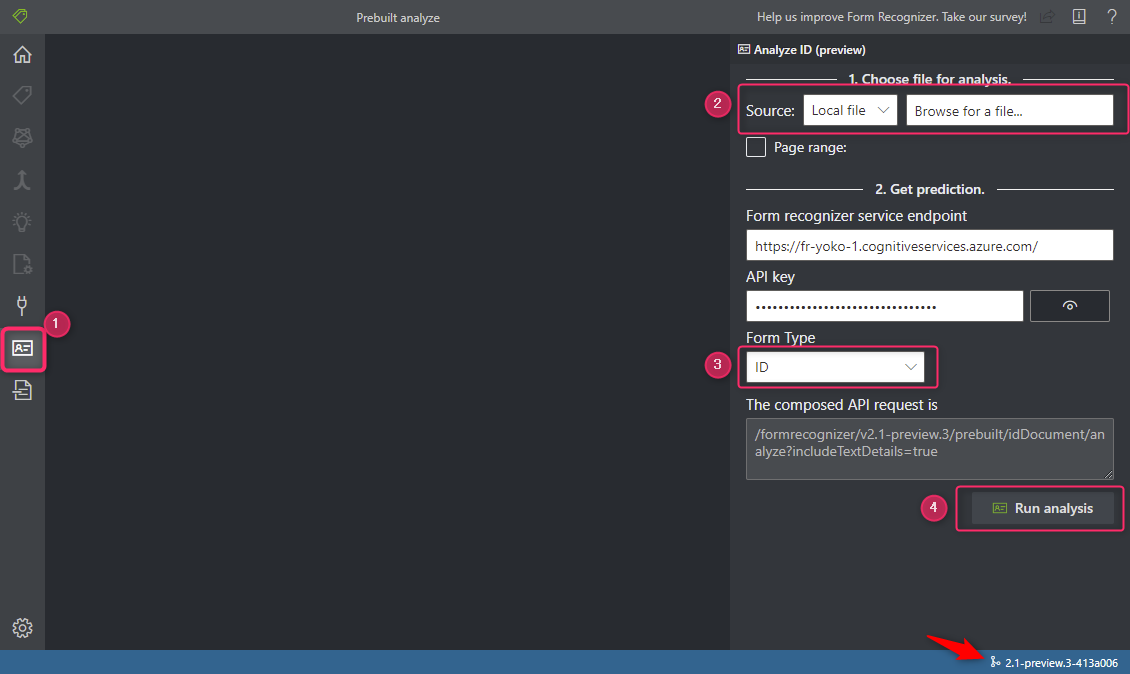
- Prebuilt analyze (図①)をクリックします。
- アップロードする写真を選択します (図②) 。URL を指定することもできますし、ローカルのファイルを指定もできます。今回はパスポートの写真を撮っておいてローカルからアップロードしました。
- Form Type は ID を指定します (図③) 。
- Run analyze をクリックすると分析が開始されます (図④) 。
メニューがない場合は、右下に表示されてる API のバージョンが異なる可能性がありますのでチェックしましょう。
結果は下図のようになりました。パスポートの情報ということでぼかしをかけたので全く伝わらない図ですが、パスポートの番号や有効期限などすべての情報がラベルと紐づいて正確に取得できました。この1枚だけの結果を見る限りだと実用性あるレベルだなぁと感じました。
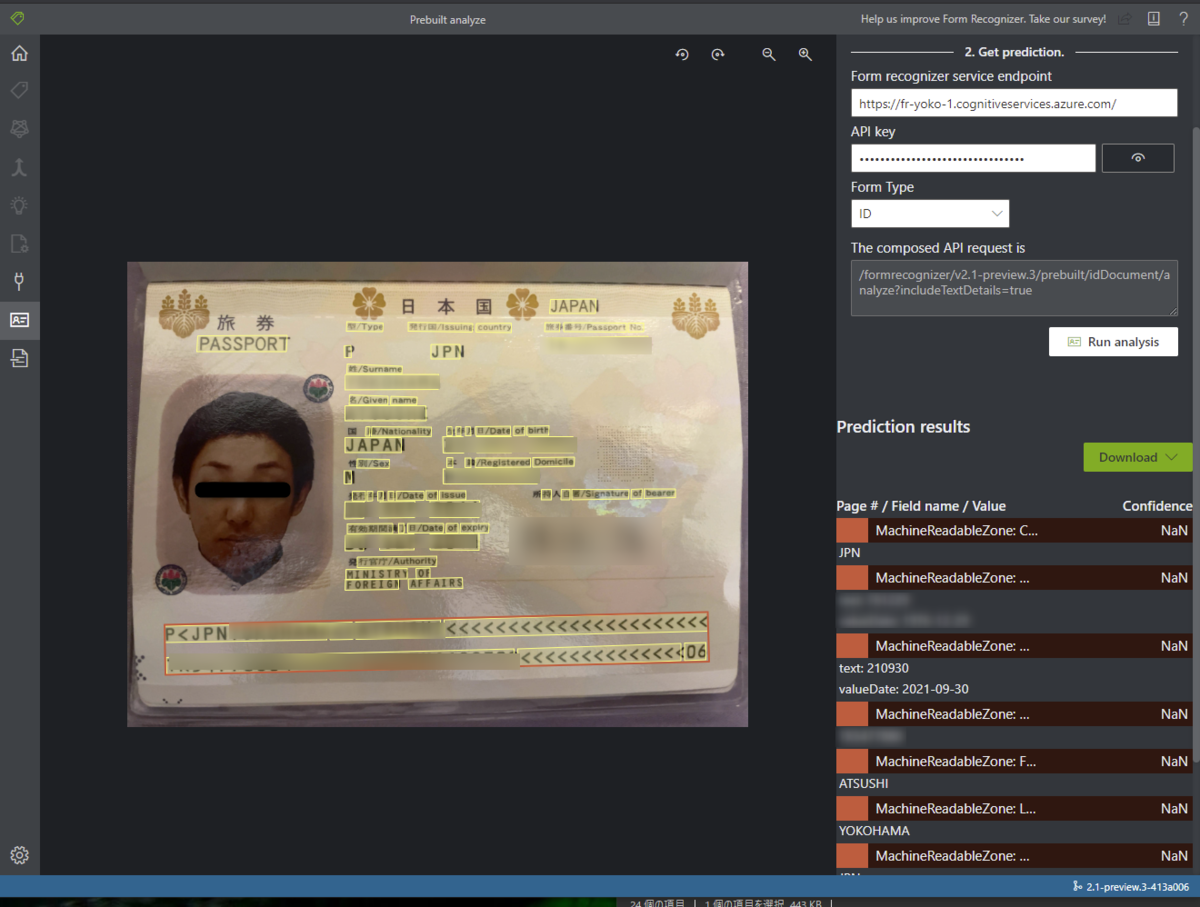
文字だけ取得するのはある程度精度のある OCR ならできると思いますが、パスポートは国によってレイアウトが全く違うこともあり単純な OCR だと実用はしんどいです。読み取った値がパスポート番号なのか、有効期限なのかとか判別するのは面倒だったのでこんなにサクッとできるとありがたいです。他国のがどれだけいい感じに取得できる希望が芽生えたので、機会があれば試してみたいですね。
終わりに
DX が進んでない組織が最初の PoC で、紙をなくすようなプロジェクトの導入として使えそうな空気を感じますね。