Microsoft Ignite November 2021 で発表された Azure Cognitive Service for Language について全体像をまとめてみました。
- Azure Cognitive Service for Language 誕生までの歴史
- 機能一覧
- Extract information
- Classify text
- Translate text
- Conversational Language Understanding
- Answer questions
- おわりに
Azure Cognitive Service for Language 誕生までの歴史
Azure Cognitive Service for Language は完全に新しい機能ではありません。既存の機能がグルーピングしなおされたプラスアルファって感じです。
具体的には、今までは以下の 3 つのサービスがありました。
- Text Analytics
- Language Understanding (LUIS)
- QnA maker
"ざっくり"いえばこの 3 つが合体してひとつになったプラスアルファって感じです。ひとつになったことによるメリットを以下のように紹介されていました。
- Azure のリソースが 1 になる
- ユーザーエクスペリエンスが 1 つになる。
- SDK が 1 つにまとまる
- 1 つの API セットになる
私も初見ではひとつにまとまっただけかって思ってしまいましたが、ちょっといじってるとこれは思った以上に良きーと感じました。
というのも Language Studio という Web のポータルが用意されており、どの機能を使うにも Language Studio から同じ操作感でドキュメントやサンプルコード、SDK にたどり着くことができます。個別にドキュメントを開くのにググる必要ないのは意外にも良いユーザーエクスペリエンスだなと感じました。
そして、とりあえずどんな感じかすぐ試せる UI が備わっているのも便利です。

既存で Text Analytics, LUIS, QnA Maker を使っている人はそのまま使い続けて問題ないし、試したければ移行パスもあるので柔軟に利用可能です。
機能一覧
Azure Cognitive Service for Language は大きく以下の 5 つのカテゴリーで構成されています。
- Extract information
- Classify text
- Answer question
- Understand conversations
- Translate text
このそれぞれの中に複数のサービスがあってかなり多くの機能があるので、それぞれをさらさらっと見ていきましょう。
Extract information
自然言語理解 (Natural Language Understanding - NLU) を使用して非構造化テキストから情報を抽出するサービス群です。このカテゴリーは今までの Text Analytics の機能が中心って感じです。個別に見ていきましょう。
key phrase extraction - キーフレーズ抽出
タイトルそのままですが文章からキーフレーズを抽出する機能で、日本語にも対応しています。
例えば「今夜の夕食はハンバーグだよ」という文章を Language Studio で試すとこんな感じ。

Extract informationの公式ドキュメントはこちら:
Azure AI Language のキー フレーズ抽出とは - Azure AI services | Microsoft Learn
Entity linking - エンティティリンク設定
現状は英語とスペイン語のサポートのみです。
公式ドキュメントでは、テキストで見つかったエンティティの id を識別しあいまいさを解消すると書いています。
具体的には、文章でエンティティを見つけて、文のコンテキストを判断して Wikipedia のリンクをつけてくれます。
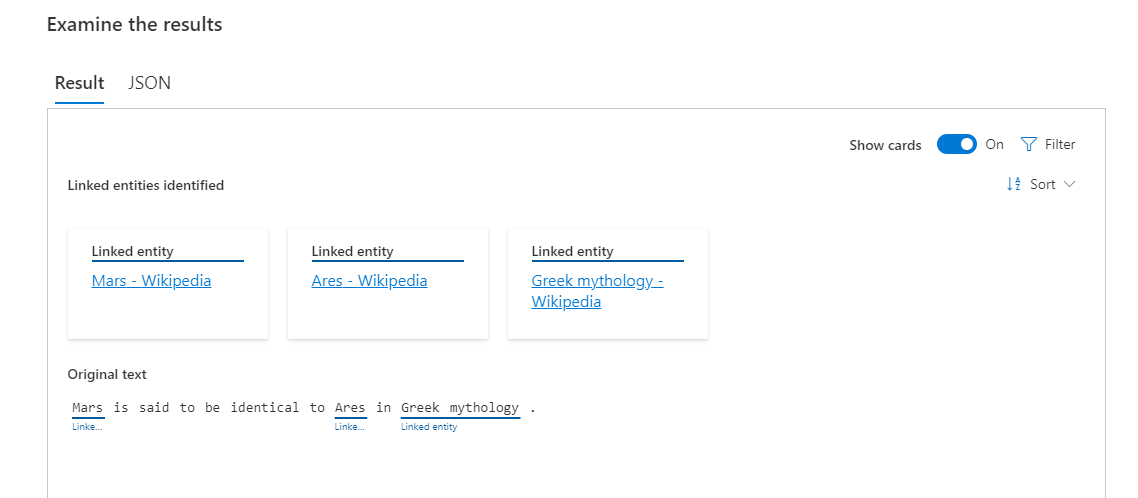
Language Studio で、"Mars" という単語について試してみましょう。"Mars" には火星という意味があるのでこんな文章を入力してみます。
「Mars is the second smallest planet in our solar system.」( "Mars" は太陽系で2番目に小さい惑星です)
結果は、火星のリンクがつけれられました。

"Mars" には別の意味もあって、ローマ神話の神である "Mars" くんを言及したテキストを入力してみます。
「Mars is said to be identical to Ares in Greek mythology.」( "Mars" は、ギリシャ神話のアレースだと言われています。)
結果は、ローマ神話の神の Mars のリンク になりました。
 Entity linking の公式ドキュメントはこちら:
Entity linking の公式ドキュメントはこちら:
Azure AI Language のエンティティ リンク設定とは - Azure AI services | Microsoft Learn
PII detection: 個人を特定できる情報の検出
Pll は Personally Identifiable Information の略で " 個人を特定できる情報"、それを検出するサービスです。日本語も対応しており、非構造化テキストに含まれる機密情報を特定、分類、編集することができます。
具体的な例だとこんなテキストを入力してみます。
「山田さんなら、yamada@contoso.com にメールすれば連絡が取れるよ。携帯は 090-999-9999 だよ。」
Language Studio での結果は、電話番号や Email が検出されます。

検出できるカテゴリーは一覧は以下です。実用レベルで結構たくさんありますね。実運用でどの程度の精度がでるか試してみたくなります。
Azure AI Language で個人識別情報(検出)によって認識されるエンティティ カテゴリ - Azure AI services | Microsoft Learn
Personally Identifiable Information (PII) detection の公式ドキュメントはこちら:
Azure AI Language の個人を特定できる情報 (PII) の検出機能とは - Azure AI services | Microsoft Learn
NER - 固有表現認識
NER は Named Entity Recognition で、"固有表現認識" のことです。
日本語にも対応済みで、文章の中で固有表現のエンティティを特定し人名や地名などのラベルをつけてくれます。
サポートされているエンティティのカテゴリーの一覧はこちらです。
Azure AI Language の 固有表現認識 によって認識されるエンティティのカテゴリ - Azure AI services | Microsoft Learn
例としてこんな文章を試してみましょう。
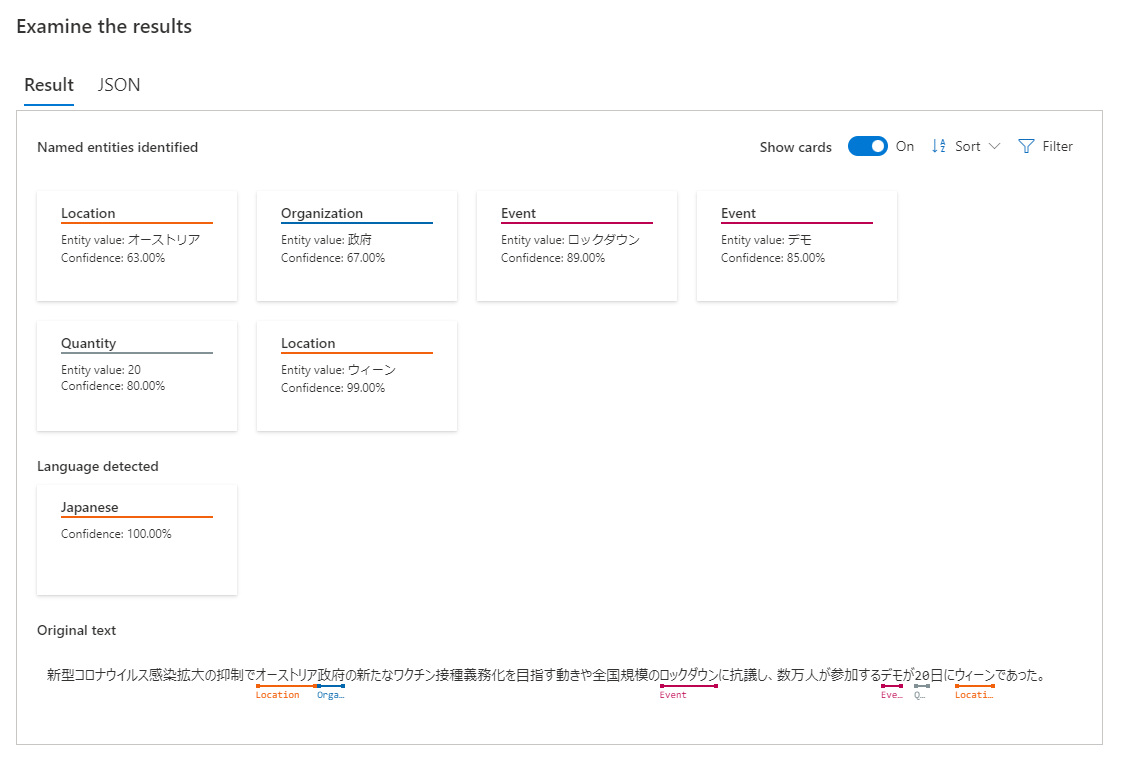
「新型コロナウイルス感染拡大の抑制でオーストリア政府の新たなワクチン接種義務化を目指す動きや全国規模のロックダウンに抗議し、数万人が参加するデモが20日にウィーンであった。」
Language Studio での結果はこうなります。場所、組織やイベントがラベリングされてきます。想像した感じですが、日付がうまく取れないなーくらいが気になり色々試したけど、ほとんラベリングされなかった。
Named Entity Recognition の公式ドキュメントはこちら:
Azure AI Language の個人を特定できる情報 (PII) の検出機能とは - Azure AI services | Microsoft Learn
custom NER - カスタム固有表現認識
日本語は未対応で、固有表現認識の機能に自身の学習データを使ってトレーニングさせ、カスタムなモデルを作れる機能です。金融機関とか医療とか専門用語が多い特定のドメインで活躍してくれそうですね (医療は Text Analytics for health が作られていますが)。
公式ドキュメントでの Named Entity Recognition の概要はこちら:
Azure AI Language の個人を特定できる情報 (PII) の検出機能とは - Azure AI services | Microsoft Learn
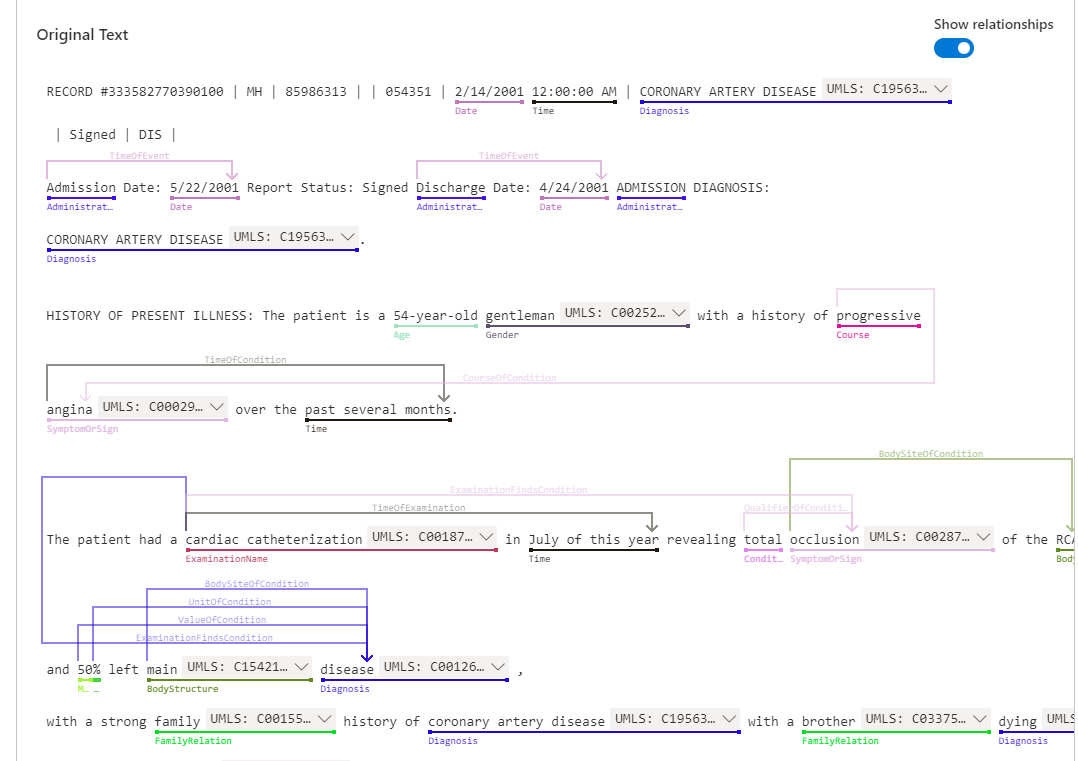
Text Analytics for health
現状では英語のみのサポートですが、医療情報に特化された Text Analytics で、主に4つの機能で構成されたサービスです。
- Named Entity Recognition
- Relation Extraction
- Entity Linking
- Assertion Detection
医師のメモ、退院要約、臨床ドキュメント、電子健康記録などの非構造化テキストから関連する医療情報が抽出されてラベルが付けられます。Microsoft Research のチームがお客さん向けにカスタマイズしたサービスのようなので、英語圏での実用レベルも高いのかもしれませんね。
Text Analytics for health の公式ドキュメントはこちら:
Azure AI Language の Text Analytics for health とは? - Azure AI services | Microsoft Learn
Text summarization - テキスト要約
日本語もサポート済みで、テキストを要約してくれる機能です。要約は "抽出型" になります。要約する文章を 1 から 20 の 範囲で指定して要約する感じです。
2021年11月時点では Language Studio にまだ含まれていないので、REST API を自分でたたく必要があります。
Classify text
自然言語理解 (Natural Language Understanding - NLU) を使用して、どの言語かを抽出したり、テキストから感情を分類するサービス群です。
Sentiment analysis and Opinion mining - 感情分析とオピニオンマイニング
感情分析は、日本語が対応しています。positive、neutral、negative と mixed のラベルがスコア 0 - 1 の範囲でラベリングされます。
オピニオンマイニングは、日本語未対応です。アスペクトベースの感情分析で、文章のより細かい粒度で単語に対する意見を評価してくれます。
Language Studio で以下の文章を書いてみましょう。
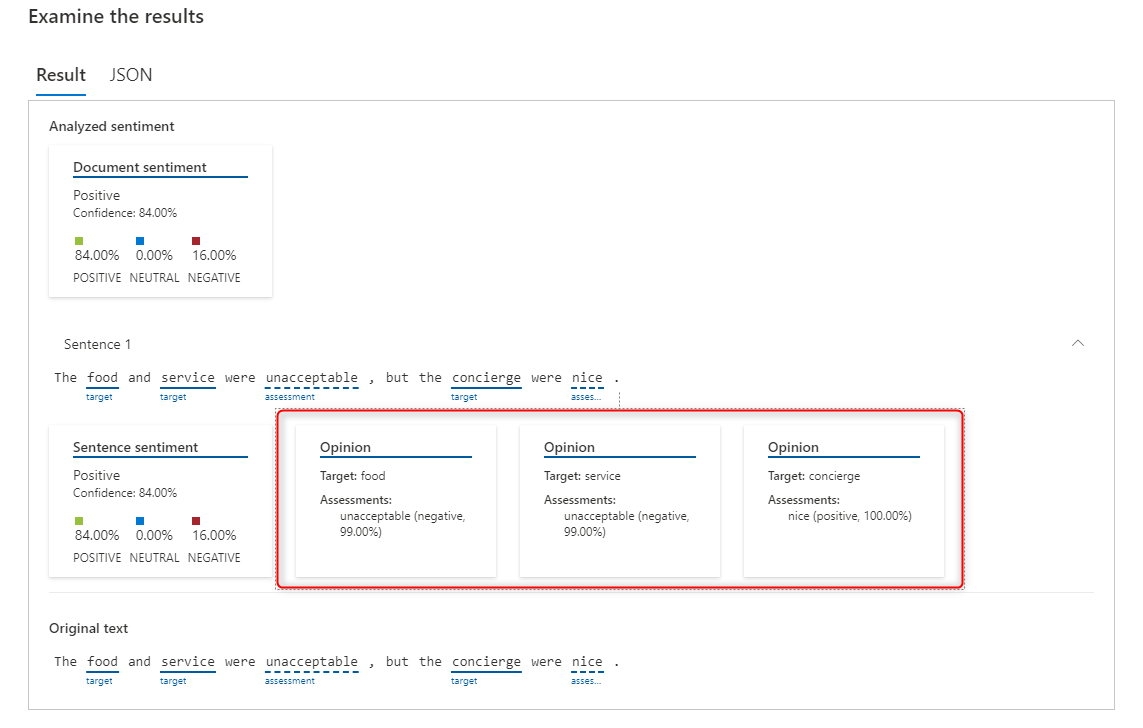
「The food and service were unacceptable, but the concierge were nice」
(食事とサービスはめっちゃまずかったけど、コンシェルジュは素晴らしかったです。)
1つの文章で negative な内容と positive な内容が混ざるとこの文章の評価は難しいのが想像できますが、オピニオンマイニングをすることでそれぞれの単語に端する感情分析が可能になります。
結果はこんな感じで、"food" と "service" には negative: 99%、"concierge" に対して positive: 100% と分析できています。
Sentiment analysis and Opinion mining の公式ドキュメントはこちら:
Language サービスの感情分析とオピニオン マイニングとは - Azure AI services | Microsoft Learn
Language Detection - 言語検出
文章からどの言語かを判断してくれる機能で、100以上の言語に対応しています。Translator では対応しているスタートレックのクリンゴン語には、Language Detection では対応していません。
Language Detection の公式ドキュメントはこちら:
Azure AI Language での言語検出とは - Azure AI services | Microsoft Learn
Custom text classification
現状では7か国語に対応してますが、日本語は未対応なので私は今のところ試すモチベーションがわいていません (汗) 。
学習データとしてテキストをアップロードしてタグ付けてトレーニングさせて評価しながら、モデルの管理もしながら、予測のエンドポイントまで公開できるサービスです。開発のライフサイクルをまるっと使える点は Cognitive Services の他の Custom できるサービスと同様でよいです♪
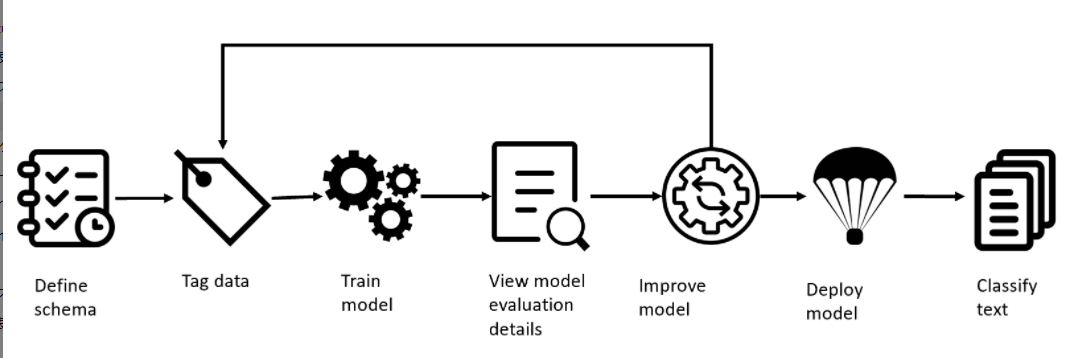
Custom text classification の公式ドキュメントはこちら:
Custom text classification - Azure AI services | Microsoft Learn
Translate text
以前の Translator のままで最近は新しい機能追加は特にないですが 100 以上の言語に対応して翻訳が可能です。
Custom Translator の機能もあり、単語や文章の辞書を学習データとしてとレーニンさせることができます。業界特有の用語や文をいい感じに翻訳する Translator を作ることができるのは強みのひとつです。
昔から Translator 専用のポータルがあるので Language Studio には今のところ入っていないですね。
Translator の公式ドキュメントはこちら:
Azure AI 翻訳とは - Azure AI services | Microsoft Learn
Conversational Language Understanding
Language Understanding (LUIS) 次世代バージョンで略語も CLU になります...もうそろそろ "ルイス" とは呼ばなくなるのかな。文章からその Intent を判断し、文中の Entity を判断してラベリングをしてくれる機能です。
すごく雑な例だと、
「明日の池袋の天気はなに?」
という文章をこんな感じで情報抽出してくれるモデルをつくることができます。
- Intent: 天気予報
- Entity:
- 場所: 池袋
- 日時: 明日
この結果をもとに例えばどっかの天気予報の API を呼ぶことで、自然言語から天気予報を教えるアプリがつくれるとかですね。
個人的にはここしばらく LUIS も触っていなかったのですが、ベースのモデルのアーキテクチャに multilingual transformer-based models を導入したりで LUIS より精度が大幅に向上しており、オーケストレーションプロジェクトを作成できる機能ができたりなどあるので、機能を一通りさわってブログにまとめたいところです。ちなみに既存の LUIS からインポートもできるので、それも試してみたいところですね。
Conversational language understanding の公式ドキュメントはこちら:
Conversational Language Understanding - Azure AI services | Microsoft Learn
Answer questions
Question Answering, Custom Question Answering
QnA Maker の進化版って位置づけで今年の5月くらいに public preview で出た Question Answering / Custom Question Answering がここで GA となりました。ざっくりな機能の一部を説明すると、質問と回答のペアを読み込ませることで、自然言語での質問を回答してくれるモデルを作ってエンドポイントを公開できるサービスです。
ちょっとざっくりすぎますが書くと長くなりそうなので、ここについても別途ブログでまとめたいと思ってはいます。
機能とは関係ない側面ですが、QnA Maker だと Azure のリソースが5つ作られるのが、今回だと2つになるところがまず嬉しいです。正確には昨年11月に出た QnA Maker managed からリソースが2つになってますけど 。
Custom Question Answering は QnA Maker managed の進化版って書いた方が適切なはずです。QnA Maker managed の機能はもちろんすべてここに引き継がれています。
Question Answering / Custom Question Answering の公式ドキュメントはこちら:
カスタム質問応答とは - Azure AI services | Microsoft Learn
おわりに
最近は、Cognitive Services のカテゴリーし直しが多いかつ、大幅に精度向上したりカスタマイズ性もよくなっています。ひとむかし前に Cognitive Services を使っていていまいち精度がでないとかで使わなくなった人も、もしかしたら実用レベルで利用できる可能性があるのではと感じました。
サービスがまとまってどかっとなったので情報量が多くなりましたが、また個別に整理できればと思います。