Cognitive Services のブログはしばらく書いてなかったし仕事でも使ってなかったので、そろそろ一通りのおさらいしようと思っています。
ということでまずは Azure の Cognitive Services の中で Vision 系のサービスのひとつ、Computer Vision API から始めます。
いきなり Computer Vision API の個人的な感想から書くと、汎用的な画像分析って意味ではいい感じに分析できるやーんって思った半面、いざ自身のアプリで何かを分類したいときには汎用的過ぎて使いどころが悩ましく感じてました。
でもよくよく考えると、オブジェクトの検知とか超優秀な気がするし、簡易なコンテンツモデレートにもいいんじゃないかとかの用途あるなーと感じてます。
ざっくりな機能はこんな感じでしょうか。
- 画像の分析
- 画像からテキストを抽出
- Docker Container 上で各種機能を実行
API リファレンスの一覧に出てる全ての機能は書きませんが、主要な機能をいくつか整理してみます。
- 1. 画像の分析
- 2. 画像からテキストを抽出
- 余談: 画像分析の API を叩いてみる
- 余談: Azure AD による認証もできる
- 3. Docker Container 上で各種機能を実行
- 終わりに
1. 画像の分析
汎用的な画像の分析でできますが、もう少し詳しく整理してみます。
タグ付け
認識した部ジェクトにタグとその精度の情報を返してくれます。タグは、1000以上を認識できるので、汎用ではあるけどすごいです。
オブジェクトの検出
タグ付けの機能と類似していて認識したオブジェクトのタグをつけてくれますが、それと合わせてその位置の情報( 認識した情報を四角で囲った際の4点の位置)を返してくれます。下図の画像を送ると、Person と Skateboard の位置を返してくれます(その座標を線で結ぶと以下の図のようになります)。

(画像: https://azure.microsoft.com/ja-jp/services/cognitive-services/computer-vision/ より)
カテゴリー分類
86のカテゴリーから分類します。86は以下のリンクを参考に。
{kind=link}
説明文
Caption (画像の説明) を出力します。複数表示します。
顔の検出
顔の場所を検出します。また、年齢と性別を表示します。感情を分析したい場合は Face API を利用します。
成人向けコンテンツの検出
API を投げる際、クエリパラメーターで Adult を追加することで分析結果を取得できます。
isAdultContent: ヌードや性的な行為の描写とかが判別します。isRacyContent: 静的なものを連想させるものかどうかを判別します。isGoryContent: 血とか描写されてるものを判別します。
より厳格?めっちゃガチな検知には、別サービスの Azure Content Moderator を使う感じです。
その他
ブランド(やブランドのロゴ)の検出や、画像種類の検出(クリップアートと線画の検出)、配色の検出などができます。
こちらに詳細の記載があります。
REST API でクエリパラメーターをつけて必要最低限のレスポンスのみを返すように制御できます。ちなみに、Categories, Tags, Descriptions, Celebrities, Landmarks は Language を ja に指定することで日本語でのレスポンス取得が可能です。
2. 画像からテキストを抽出
現状では、Read API、OCR API、Recognize Text APIの 3 つがありますが、Recognize Text API はもう非推奨で Read API を使ってねって話になってるので、実質は2つでしょう。
Read API
Recognize Text API の後継サービス(?)として、比較的新しい API です。v3.0 も2020年2月にプレビューが始まりました。
非同期で使う、つまり使い方は、画像を分析用の API に投げる → 読み取り完了後にあらためて結果取得の API を投げることで解析結果が見る API です。
読み取れるファイルは JPEG、PNG、BMP、PDF、TIFF で、画像のサイズは 5050 ~ 1000010000 ピクセル、20 MB 未満です。
対応言語が英語とスペイン語のみ....じゃーおわこんの Recognize Text API かぁ...と思いそうですが、こっちも英語のみのサポートです。
OCR API
Read API が非同期だったのに比べ、OCR API は同期的、つまり画像を投げたらそのレスポンスで結果が返ってきます。画像の対応サイズが Read API より小さく、5050 ~ 42004200ピクセルです。
言語は日本語もサポートされているほか、たくさんの言語がサポートされています(くわしくはこちら)。
余談: 画像分析の API を叩いてみる
概要を整理しただけだと寂しいので軽く 画像の分析の API を叩いてみましょう。基本的に REST API でアクセスできますが、.NET, Python, Java, Node.js の SDK が用意されているのでコード書くのも容易ですが、今回はコード書かずに行きます。
まず、サブスクリプションを持っていない場合、2019年10月ごろから以下リンクの制限付きで"12カ月無料で利用できる"枠に Computer Vision も仲間入りしたので、以下のリンクから申し込んでの利用もできます。
(サブスクリプションを持っている身なので個人的には試したことないです。)
Azure Portal で API キー作成
Azure Portal でリソースを作成する際、注意したいポイントは2点。
1つ目は、キーには2種類あることです。
- マルチサービスのキー: Computer Vision や Face, LUIS といった複数のサービスを共通して使えるキー。複数のサービスをまとめて使うならキーの管理が楽になるし、課金も統合されます。Azure Portal でリソースの作成する時は、"Cognitive Services" で検索して作成します。
- 単一サービスのキー: Computer Vision や Face API とかそれぞれのサービスしか利用できない専用のキー。Free レベルはこちらにしかない(と思う)。Azure Portal でリソースの作成する時は、今回なら "Computer Vision" で検索して作成します。
多少の料金プランが違うくらいの差はありますが、Computer Vision ならどちらでも利用できます。マルチサービスのキーで他にどのサービスが利用できるかとかの詳しい話は以下のドキュメントを参考にしましょう。
Azure portal を使用して Cognitive Services リソースを作成する
2つ目の注意点は、キーはエンドポイントに対して作成されます。つまりどのリージョンを選択するするかはちょっとだけ重要です。
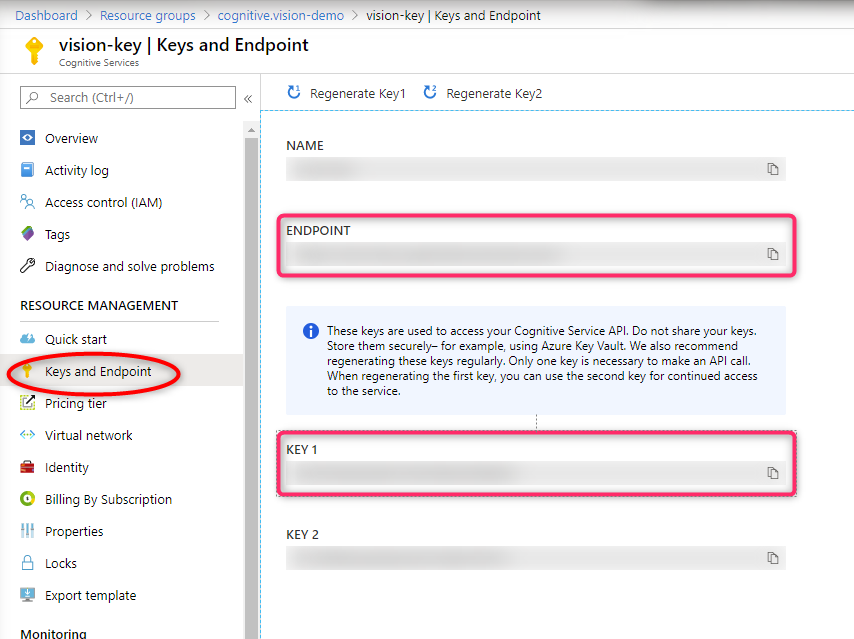
Azure Portal でキーとエンドポイントの確認
作成したリソースを開いて Keys and Endpoint (日本語での表示の場合、それっぽい名称とアイコンから判断できると思います)を開くと表示されます。すぐ使うのでメモしておきます。
REST API で送信
ではさっそく送信してみましょう。画像を分析するには、Analyze Image API を使います。 API リファレンスを見ると、URL はこう書いています。
https://{endpoint}/vision/v2.0/analyze[?visualFeatures][&details][&language]
[ ] で囲まれた部分はオプションですね。
VS Code の拡張機能 REST Client を入れると、http という拡張子のファイルを準備しておくことでいい感じで REST API が叩けます。
これを使って試しましょう。オプションなしで、 以下のように画像の URL を送信してみます。
※ <your endpoint> は自身のエンドポイントのURLに、 <your key> は自身のキーに置き換えます。画像の URL も適当に置き換えます。
POST https://<your endpoint>.cognitiveservices.azure.com/vision/v2.0/analyze
Ocp-Apim-Subscription-Key: <your key>
Content-Type: application/json
{ "url": "https://azurecomcdn.azureedge.net/cvt-0d588ba495e54c9bbf7f95a4e6cd4a0760eea15d722a512592899eef9e3d4efa/images/shared/cognitive-services-demos/analyze-image/analyze-3-thumbnail.jpg"}
Send Request をクリックすると送信されます。
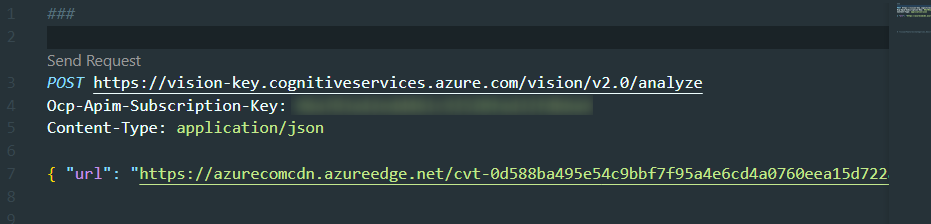
オプションをつけないと、カテゴリーと画像のメタデータのみが返ってきます。

オプションをつけて送信してみましょう。 API リファレンスの Request parameters > VisualFeatures をいくつかつけると細かい情報が表示されます。また、言語を日本語に変えてみました。
https://<your endpoint>.cognitiveservices.azure.com/vision/v2.0/analyze?visualFeatures=Categories,Description,Tags&details=Landmarks&language=ja
分析の結果が増えています。
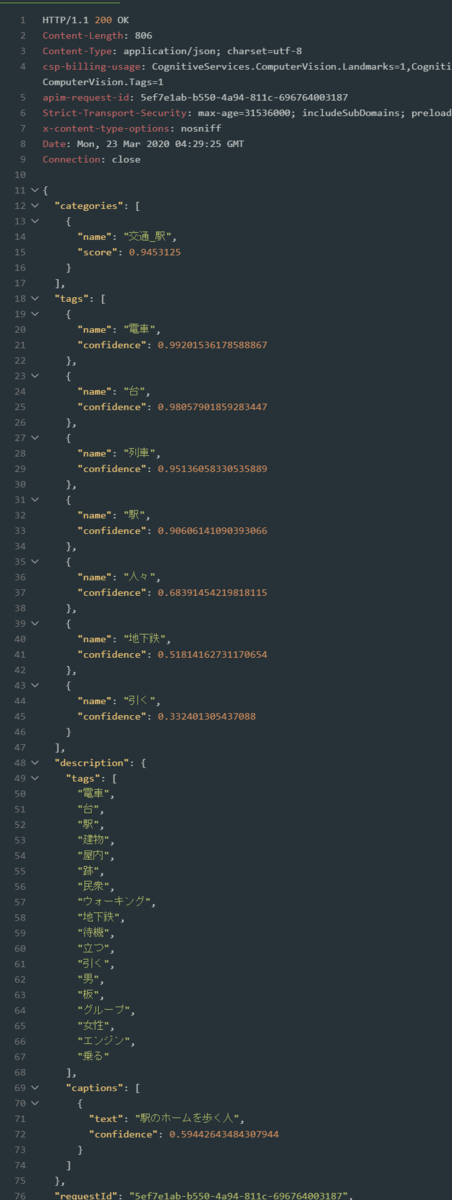
今回は駅の画像ですが、もし人の画像があるなら、visualFeatures のオプションで Face を追加すると顔の位置と年齢・性別を返します。より詳しい顔の情報を分析したいときは Computer Vision API ではなく Face API を使います。
余談: Azure AD による認証もできる
余談が続きますが、Cognitive Services で Computer Vision を含めた一部のサービス(随時増えてる途中)では、Azure AD での認証で利用することも可能になっています。2019年8月ごろからプレビューで始まりましたが、GA のアナウンスは見てない気がしてます。ドキュメントにプレビュー中とか書いてないけど GA してんのかな...
試したい方は、詳しくはこちらを参考にしましょう。
3. Docker Container 上で各種機能を実行
Cognitve Services は、Docker Container 上で動作して API を叩くことができるサービスがいくつかありますが、その一つが Custom Vision です。
利用するには、こちらのドキュメントにあるフォームから申請が必要です。
利用の前提条件とはドキュメントに書いてますのでチェックしましょう。Docker で利用できるということは、つまり ACI や Kubernetes の上でも利用できるので、低レイテンシーを求められる環境で活躍ができるわけですね。
また、注意したい点として、約10分~15分毎に課金の API への接続が走ります。10回施行されるのでそこでエンドポイントに到達できる必要があります。
終わりに
汎用の画像分析の API なので色んなことが幅広くできる分、自分のシステムに取り込んで使うには、ほしい結果がでないことがあります。 その際は転移学習を使ってトレーニングができる Custom Vision を使います。
これについても色々とアップデートがあって触れてないので、そのうちブログでも書こうかと思っています。
2019 年にいくつかハンズオンコンテンツは似たやつをいくつか作ってるんですよね。更新してないので危うそうな気がしますが....